

Excel เป็นเครื่องมือการจัดการและวิเคราะห์ข้อมูลที่มีประสิทธิภาพ เหมาะอย่างยิ่งสำหรับการรายงานและการคำนวณอย่างรวดเร็ว แต่ Python จะช่วยได้เมื่องานยุ่งเหยิง ซ้ำซาก หรือใหญ่เกินไป Python เปิดระบบอัตโนมัติ การวิเคราะห์ขั้นสูง และความเป็นไปได้ในการบูรณาการที่นอกเหนือไปจากฟีเจอร์ในตัวของ Excel ไลบรารี Python เช่น pandas สำหรับการจัดการข้อมูลและ openpyxl สำหรับการจัดการไฟล์ Excel โดยตรงทำให้สิ่งนี้ราบรื่น
ในบทช่วยสอนนี้ เราจะแสดงห้าสิ่งที่คุณสามารถทำได้ด้วย Excel + Python
พิจารณาตัวอย่างข้อมูลการขายเพื่อสำรวจห้าสิ่งที่คุณสามารถทำได้ด้วย Excel และ Python
1. ทำความสะอาดและสร้างมาตรฐานข้อมูล Excel ที่ยุ่งเหยิง (ทำซ้ำ)
เป็นเรื่องปกติที่จะมีข้อมูลยุ่งเหยิงใน Excel เนื่องจากข้อมูลในชีวิตจริงไม่ค่อยสะอาด บ่อยครั้งที่ข้อมูลมีการเว้นวรรคเพิ่มเติม การใช้อักษรตัวพิมพ์ใหญ่ผสม ตัวเลขที่จัดเก็บเป็นข้อความ การจัดรูปแบบที่ไม่สอดคล้องกัน ค่าที่หายไป รายการซ้ำ หรือข้อมูลที่ต้องมีการปรับโครงสร้างใหม่ก่อนการวิเคราะห์ ปัญหานี้ทำลายสูตรและการวิเคราะห์
Python เป็นเลิศในงานทำความสะอาดข้อมูล คุณสามารถเขียนสคริปต์ที่สร้างมาตรฐานให้กับรูปแบบข้อมูลในไฟล์ต่างๆ กรอกค่าที่หายไปโดยใช้วิธีการที่ชาญฉลาด ลบรายการที่ซ้ำกัน แบ่งหรือรวมคอลัมน์ตามรูปแบบ และตรวจสอบความถูกต้องของข้อมูลตามกฎเกณฑ์ทางธุรกิจ ขั้นตอนเหล่านี้อาจต้องใช้เวลาหลายชั่วโมงในการค้นหาและแทนที่ด้วยตนเองใน Excel เมื่อใช้ Python คุณสามารถสร้างสคริปต์ที่ทำซ้ำได้ซึ่งประมวลผลแถวหลายพันแถวในไม่กี่วินาที
สมมติว่าคุณได้รับข้อมูลการขายที่ยุ่งเหยิง ลองใช้สคริปต์ Python ที่อ่านข้อมูลที่ยุ่งเหยิง ทำความสะอาดและสร้างมาตรฐานให้กับคอลัมน์ และเพิ่มฟิลด์จากการคำนวณ
- รายได้ =หน่วย * ราคาต่อหน่วย
- รายได้สุทธิ =รายได้ * (1 – DiscountPct)
import pandas as pd
file_path = "SalesData.xlsx"
df = pd.read_excel(file_path, sheet_name="Sales Data")
# Clean types
df["Units"] = pd.to_numeric(df["Units"], errors="coerce").fillna(0).astype(int)
df["UnitPrice"] = pd.to_numeric(df["UnitPrice"], errors="coerce").fillna(0.0)
df["DiscountPct"] = pd.to_numeric(df["DiscountPct"], errors="coerce").fillna(0.0)
df["Returned"] = (
df["Returned"].astype(str).str.strip().str.lower()
.map({"yes": True, "no": False})
.fillna(False)
)
# Add calculated fields
df["Revenue"] = df["Units"] * df["UnitPrice"]
df["NetRevenue"] = df["Revenue"] * (1 - df["DiscountPct"])
# Write back into the SAME file as a NEW sheet
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
df.to_excel(writer, sheet_name="CleanData", index=False)
print("Saved CleanData sheet inside:", file_path)
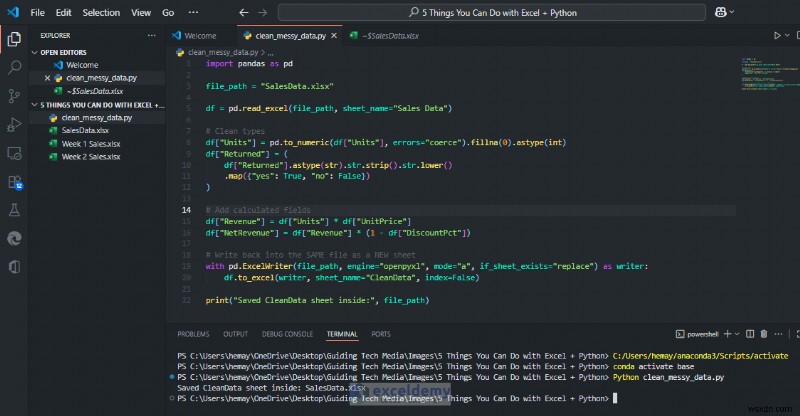
คุณจะได้รับชีตใหม่ที่มีชุดข้อมูลที่สะอาดซึ่งจะไม่ทำให้ pivot แผนภูมิ หรือการค้นหาเสียหาย ใน Excel คุณสามารถใช้เดือย/แผนภูมิจากข้อมูลที่ล้างข้อมูลต่อไปได้ โดยรู้ว่าข้อมูลมีความสอดคล้องกันทุกครั้ง
2. สร้างสรุปอัตโนมัติ (รายงานซ้ำได้)
Excel มีการจำกัดแถวและอาจช้าลงด้วยการคำนวณที่ซับซ้อน หมีแพนด้าของ Python ไลบรารีจัดการชุดข้อมูลขนาดใหญ่ได้อย่างมีประสิทธิภาพและคำนวณได้รวดเร็วยิ่งขึ้น
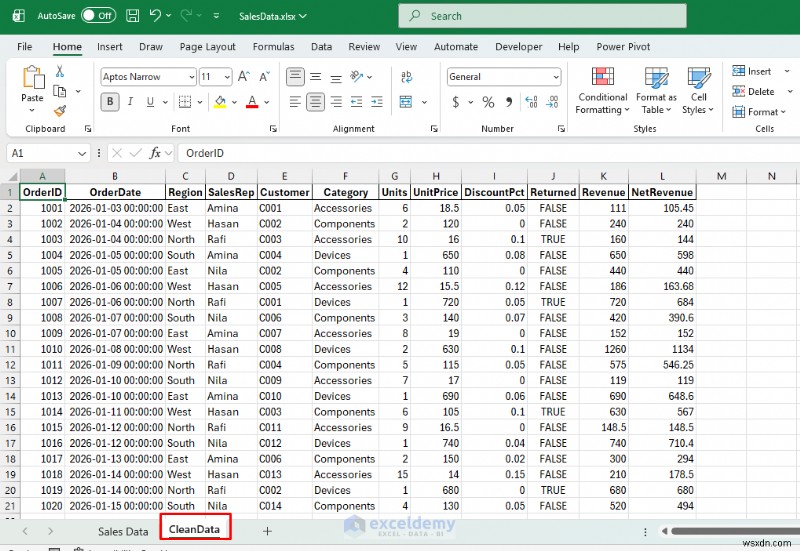
กับหมีแพนด้า คุณสามารถทำงานกับชุดข้อมูลที่มีบันทึกนับล้าน ทำการจัดกลุ่มและการดำเนินการรวบรวมที่ซับซ้อน และดำเนินการวิเคราะห์ทางสถิติที่อาจทำไม่ได้ใน Excel Python สามารถสร้างข้อมูลสรุปแบบ Pivot และส่งออกไปยัง Excel ได้ สมมติว่าคุณต้องการสรุปสั้นๆ ตามภูมิภาคและหมวดหมู่ แต่คุณไม่ต้องการสร้างจุดเปลี่ยนใหม่ทุกครั้ง
import pandas as pd
file_path = "SalesData.xlsx"
clean_sheet = "CleanData"
out_sheet = "Summary"
df = pd.read_excel(file_path, sheet_name=clean_sheet)
summary = (
df.groupby(["Region", "Category"], as_index=False)
.agg(
Orders=("OrderID", "count"),
Units=("Units", "sum"),
NetRevenue=("NetRevenue", "sum"),
Returns=("Returned", "sum")
)
)
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
summary.to_excel(writer, sheet_name=out_sheet, index=False)
print(f"✅ Saved '{out_sheet}' sheet inside: {file_path}")
คุณจะได้รับข้อมูลสรุปรายรับตามภูมิภาค ซึ่งเป็นแผ่นสไตล์ Pivot ที่พร้อมแชร์ซึ่งจะอัปเดตทุกครั้งที่คุณเรียกใช้สคริปต์อีกครั้ง
3. สร้างแผนภูมิจากข้อมูล Excel (โดยไม่ต้องจัดรูปแบบด้วยตนเอง)
แผนภูมิมักเป็นส่วนที่ใช้เวลามากที่สุดในการรายงาน Excel มีแผนภูมิมาตรฐาน แต่ไลบรารีการแสดงภาพของ Python เช่น Matplotlib , เกิดในทะเล และ โครงเรื่อง ให้ความยืดหยุ่นและความซับซ้อนมากยิ่งขึ้น คุณสามารถสร้างการแสดงภาพที่กำหนดเองซึ่งจะอัปเดตโดยอัตโนมัติเมื่อข้อมูลของคุณเปลี่ยนแปลง สร้างแดชบอร์ดเชิงโต้ตอบที่ผู้ใช้สามารถสำรวจ หรือสร้างกราฟิกคุณภาพสิ่งพิมพ์พร้อมการควบคุมทุกองค์ประกอบอย่างแม่นยำ
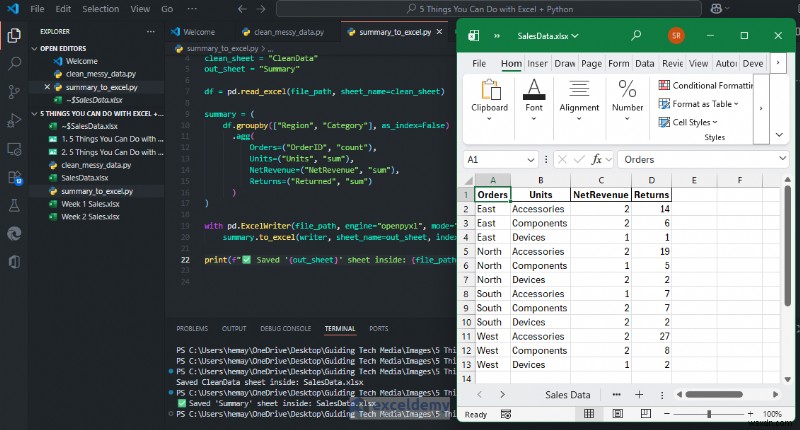
มาดูประสิทธิภาพตามภูมิภาคกัน (NetRevenue ตามภูมิภาค)
import pandas as pd
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
file_path = "SalesData.xlsx"
source_sheet = "CleanData"
output_sheet = "RegionChart" # data + chart in this one sheet
# Prepare chart data (NetRevenue by Region)
df = pd.read_excel(file_path, sheet_name=source_sheet)
chart_data = (
df.groupby("Region", as_index=False)["NetRevenue"]
.sum()
.sort_values("NetRevenue", ascending=False)
)
# Write chart data into output_sheet (same workbook)
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
chart_data.to_excel(writer, sheet_name=output_sheet, index=False)
# Add the native Excel chart on the same sheet
wb = load_workbook(file_path)
ws = wb[output_sheet]
chart = BarChart()
chart.title = "Net Revenue by Region"
chart.y_axis.title = "Net Revenue"
chart.x_axis.title = "Region"
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, "D2") # place chart to the right of the data table
wb.save(file_path)
print(f"✅ Chart Created: {output_sheet}")
ตอนนี้คุณมีข้อมูลสรุปรายได้ตามภูมิภาคพร้อมแผนภูมิแท่งแล้ว
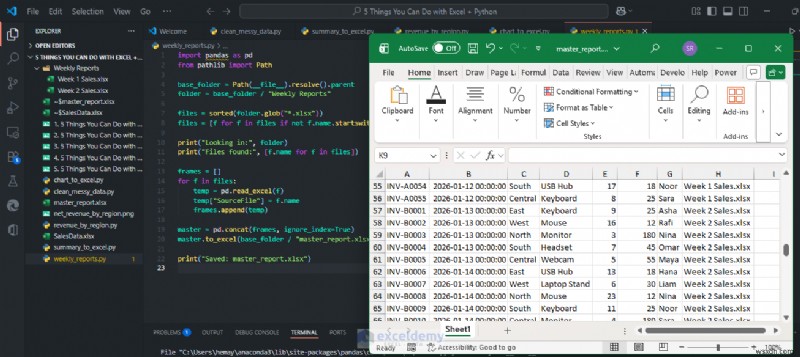
4. รวมไฟล์ Excel จำนวนมากไว้ในตารางหลักเดียว
เป็นเรื่องปกติที่จะรวมข้อมูลรายสัปดาห์ รายเดือน หรือรายไตรมาสจากแหล่งต่างๆ การรวมไฟล์ Excel จากบุคคลหรือทีมต่างๆ ทำได้ช้าและเกิดข้อผิดพลาดได้ง่าย Python สามารถรวมพวกมันเข้าด้วยกันในไม่กี่วินาทีและติดตามไฟล์ต้นฉบับ
มารวมไฟล์รายสัปดาห์ลงในโฟลเดอร์ชื่อ รายงานรายสัปดาห์/ (ทั้งหมดมีคอลัมน์เดียวกัน)
import pandas as pd
from pathlib import Path
base_folder = Path(__file__).resolve().parent
folder = base_folder / "Weekly Reports"
files = sorted(folder.glob("*.xlsx"))
files = [f for f in files if not f.name.startswith("~$")] # ignore Excel lock files
print("Looking in:", folder)
print("Files found:", [f.name for f in files])
frames = []
for f in files:
temp = pd.read_excel(f)
temp["SourceFile"] = f.name
frames.append(temp)
master = pd.concat(frames, ignore_index=True)
master.to_excel(base_folder / "master_report.xlsx", index=False)
print("Saved: master_report.xlsx")
คุณจะได้รับตารางรวมหนึ่งตารางที่มี SourceFile คอลัมน์สำหรับการตรวจสอบ ทุกสัปดาห์ คุณเพียงแค่ต้องเรียกใช้สคริปต์
5. ทำนายสิ่งที่ Excel ไม่สามารถทำได้ง่ายๆ (ตัวอย่างการเรียนรู้ของเครื่อง)
คุณสามารถประเมินความเสี่ยงในการคืนสินค้าได้โดยใช้รูปแบบ (ส่วนลด หมวดหมู่ หน่วย ราคา) จากนั้นเขียนความน่าจะเป็นกลับเพื่อให้ผู้ใช้ Excel สามารถกรองและจัดเรียงได้ Python สามารถดำเนินการแมชชีนเลิร์นนิงได้อย่างง่ายดาย
ของเราเป็นชุดข้อมูลขนาดเล็ก ยังคงแสดงขั้นตอนการทำงาน
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
file_path = "SalesData.xlsx"
df = pd.read_excel(file_path, sheet_name="CleanData")
X = df[["Region", "SalesRep", "Category", "Units", "UnitPrice", "DiscountPct"]]
y = df["Returned"].astype(int)
cat_cols = ["Region", "SalesRep", "Category"]
num_cols = ["Units", "UnitPrice", "DiscountPct"]
preprocess = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(handle_unknown="ignore"), cat_cols),
("num", "passthrough", num_cols),
]
)
model = Pipeline(steps=[
("prep", preprocess),
("clf", LogisticRegression(max_iter=1000))
])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model.fit(X_train, y_train)
# Predict probability of return for all rows
df["ReturnProb"] = model.predict_proba(X)[:, 1]
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
df.to_excel(writer, sheet_name="WithReturnRisk", index=False)
ใน Excel ให้สำรวจ WithReturnRisk และกรอง ReturnProb จากสูงไปต่ำเพื่อดูว่าคำสั่งซื้อใดดูมีความเสี่ยง
Python ใน Excel (หากมีใน Excel ของคุณ)
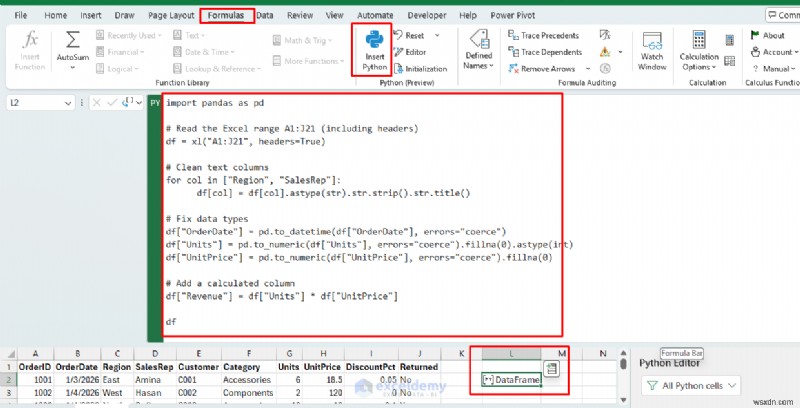
หาก Excel บนคอมพิวเตอร์ของคุณมี Python (แสดงตัวอย่าง) คุณสามารถเรียกใช้ Python ได้โดยตรงในเซลล์และส่งผลลัพธ์กลับไปยังแผ่นงาน (ดูภาพรวมของ Python ใน Excel ของ Microsoft .) ต่อไปนี้คือตัวอย่างง่ายๆ ตัวอย่างหนึ่งที่อ่านช่วงเล็กๆ ทำความสะอาดข้อความ คำนวณรายได้ และส่งกลับตารางที่สะอาด
- ใน Excel ให้ป้อนชุดข้อมูลของคุณ
- คลิกเซลล์ว่าง
- ไปที่สูตร แท็บ>> เลือก แทรก Python
- วางสคริปต์ Python
import pandas as pd
# Read the Excel range A1:J21 (including headers)
df = xl("A1:J21", headers=True)
# Clean text columns
for col in ["Region", "SalesRep"]:
df[col] = df[col].astype(str).str.strip().str.title()
# Fix data types
df["OrderDate"] = pd.to_datetime(df["OrderDate"], errors="coerce")
df["Units"] = pd.to_numeric(df["Units"], errors="coerce").fillna(0).astype(int)
df["UnitPrice"] = pd.to_numeric(df["UnitPrice"], errors="coerce").fillna(0.0)
# Add a calculated column
df["Revenue"] = df["Units"] * df["UnitPrice"]
df
มันจะส่งคืน DataFrame ซึ่งเป็นวัตถุตารางของ Python Excel จะแสดงเป็นตัวอย่างตาราง (และการ์ด)
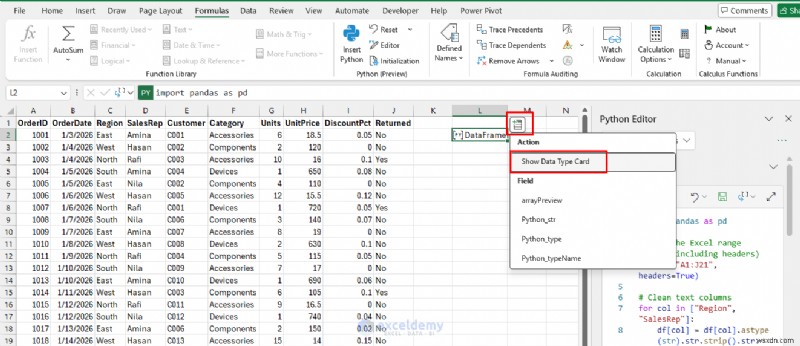
ตอนนี้ "กระจาย" เอาต์พุตลงในเซลล์เหมือนตารางที่สะอาด
- คลิกที่ แทรกข้อมูล จาก DataFrame>> เลือก แสดงการ์ด DataType เพื่อดูตัวอย่างตาราง
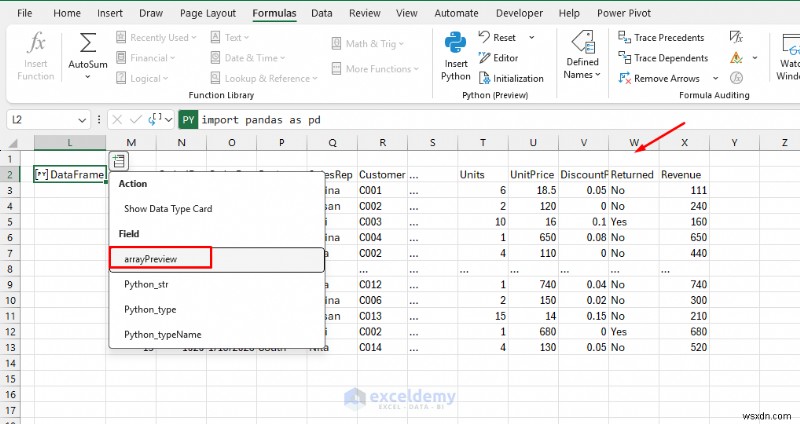
- เลือก arrayPreview เพื่อนำตารางเข้าสู่ Excel
- ขณะนี้คุณมีข้อความมาตรฐานและรายได้ใหม่ คอลัมน์
บทสรุป
บทความนี้จะแสดงห้าสิ่งที่คุณสามารถทำได้ด้วย Excel + Python Excel มีประสิทธิภาพมากขึ้นด้วย Python การล้างชุดข้อมูลที่ยุ่งเหยิง สร้างการสรุปแบบ Pivot ทำให้แผนภูมิเป็นอัตโนมัติ รวมไฟล์ Excel จำนวนมาก และเพิ่มข้อมูลเชิงลึกของ Machine Learning แบบง่ายๆ ได้ง่ายขึ้น การรวม Excel และ Python เข้าด้วยกันทำให้เวิร์กโฟลว์คล่องตัวขึ้น ตั้งแต่การนำเข้า/ส่งออกข้อมูลไปจนถึงระบบอัตโนมัติและการแสดงภาพ เริ่มต้นด้วยสคริปต์เล็กๆ และทดลองกับไลบรารีเพิ่มเติม
รับแบบฝึกหัด Excel ขั้นสูงพร้อมโซลูชันฟรี!