

นิพจน์ทั่วไป (regex) อาจดูซับซ้อนในตอนแรก แต่เป็นเครื่องมือที่มีประสิทธิภาพสำหรับการจับคู่รูปแบบและการจัดการข้อความ ใน Excel อนุญาตให้คุณค้นหา แยก และแทนที่ข้อมูลตามรูปแบบที่ซับซ้อน ทำให้งานต่างๆ เช่น การล้างข้อมูล การตรวจสอบความถูกต้อง และการแยกวิเคราะห์ มีประสิทธิภาพมากขึ้น พวกเขาสามารถประหยัดเวลาหลายชั่วโมงในการทำความสะอาด การตรวจสอบ และการดึงข้อมูลเมื่อคุณเรียนรู้พื้นฐานแล้ว เพื่อรองรับ regex นั้น Excel มีฟังก์ชันต่างๆ เช่น REGEXTEST, REGEXEXTRACT และ REGEXREPLACE
นี่คือหลักสูตรเร่งรัด Regex สำหรับผู้ใช้ Excel ระดับสูง
Regex คืออะไร
Regex (นิพจน์ทั่วไป) เป็นภาษารูปแบบสำหรับข้อความ แทนที่จะค้นหาหรือจับคู่คำที่ตรงกันทุกประการ regex ให้คุณอธิบายรูปร่างของข้อความได้ ใน Excel นั้น regex เปรียบเสมือนการรวม FIND + MID + SUBSTITUTE เข้าด้วยกัน โดยที่รูปแบบเดียวสามารถตรวจสอบ แยก หรือล้างข้อความได้
คุณสามารถจับคู่โครงสร้างทั่วไปใน Excel ได้โดยใช้ regex:ที่อยู่อีเมล หมายเลขโทรศัพท์ วันที่ในรูปแบบต่างๆ หรือ ID ใดๆ ที่เป็นไปตามกฎ
ใน Excel สมัยใหม่ คุณใช้ Excel เป็นหลักกับ:
- REGEXTEST (ตรวจสอบว่ามีรูปแบบอยู่หรือไม่)
- REGEXEXTRACT (ดึงส่วนที่ตรงกัน)
- REGEXREPLACE (แทนที่/ล้างการจับคู่)
พื้นฐาน Regex:รูปแบบการสร้าง
รูปแบบ Regex คือสตริงที่กำหนดสิ่งที่คุณกำลังมองหา โดยจะรวมอักขระตามตัวอักษร (เช่น “abc”) เข้ากับอักขระเมตาพิเศษ คุณสามารถใช้ตารางนี้เป็นข้อมูลอ้างอิงด่วนได้
อักขระเมตาและไวยากรณ์หลัก:
- ปริมาณ (*, +, ?, {}) ใช้กับองค์ประกอบที่อยู่ข้างหน้า
- ติดธง: ฟังก์ชัน regex ของ Excel ไม่รองรับแฟล็กอินไลน์ เช่น (?i) ในรูปแบบ; ใช้อาร์กิวเมนต์ของฟังก์ชันสำหรับการพิจารณาตัวพิมพ์เล็กและตัวพิมพ์ใหญ่ (เช่น อาร์กิวเมนต์ที่สามของ REGEXTEST) หรือใช้คลาสอักขระ (เช่น [Aa])
- โลภกับขี้เกียจ: ตามค่าเริ่มต้น ตัวระบุปริมาณจะโลภมาก (จับคู่ให้มากที่สุด) เพิ่ม ? หลังตัวระบุเพื่อทำให้ขี้เกียจ (เช่น .*?)
ฟังก์ชัน Regex ของ Excel
Excel มีฟังก์ชัน regex สามฟังก์ชันโดยกำเนิด ฟังก์ชันเหล่านี้ใช้สตริงข้อความและรูปแบบนิพจน์ทั่วไปเป็นอินพุต และตรวจสอบหรือแปลงข้อความตามรูปแบบ มาทำความรู้จักกับแต่ละฟังก์ชันก่อนเริ่มหลักสูตรกัน
ไวยากรณ์:
=REGEXTEST(text, pattern, [case_sensitivity])
ฟังก์ชันนี้จะตรวจสอบว่ารูปแบบตรงกับส่วนใดส่วนหนึ่งของข้อความที่ให้มาหรือไม่ ส่งคืน TRUE หากรูปแบบตรงกับที่ใดก็ได้ในข้อความ FALSE มิฉะนั้น
- ข้อความ: การอ้างอิงข้อความหรือเซลล์ที่คุณต้องการทดสอบ
- รูปแบบ: รูปแบบนิพจน์ทั่วไป (regex) ที่อธิบายข้อความที่คุณต้องการจับคู่
- [ความไวต่อขนาดตัวพิมพ์]: กำหนดว่าการจับคู่จะคำนึงถึงขนาดตัวพิมพ์หรือไม่ ตามค่าเริ่มต้น การจับคู่จะพิจารณาตัวพิมพ์เล็กและตัวพิมพ์ใหญ่
- 0: คำนึงถึงขนาดตัวพิมพ์
- 1: ไม่คำนึงถึงขนาดตัวพิมพ์
ฟังก์ชันนี้จะคืนค่า TRUE หาก A1 มีตัวเลขสามหลักติดต่อกัน
ไวยากรณ์:
=REGEXEXTRACT(text, pattern, [return_mode], [case_sensitivity])
ฟังก์ชันนี้จะแยกข้อความที่ตรงกัน
- [return_mode]: ตัวเลขที่ระบุสตริงที่คุณต้องการแยก ตามค่าเริ่มต้น โหมดส่งคืนจะเป็น 0.
- 0: ส่งกลับสตริงแรกที่ตรงกับรูปแบบ
- 1: ส่งกลับสตริงทั้งหมดที่ตรงกับรูปแบบเป็นอาร์เรย์
- 2: ส่งคืนกลุ่มการจับจากการจับคู่แรกเป็นอาร์เรย์
=REGEXEXTRACT(A1, "\d{3}-\d{3}-\d{4}")
แยกหมายเลขโทรศัพท์ เช่น “123-456-7890”
ไวยากรณ์:
=REGEXREPLACE(text, pattern, replacement, [occurrence], [case_sensitivity])
ฟังก์ชันนี้จะแทนที่รายการที่ตรงกันด้วยข้อความใหม่
- การแทนที่: ข้อความที่คุณต้องการใช้แทนรูปแบบ คุณสามารถอ้างอิงกลุ่มการจับด้วย $1, $2, ฯลฯ
- เหตุการณ์: ระบุอินสแตนซ์ของรูปแบบที่คุณต้องการแทนที่ ตามค่าเริ่มต้น การเกิดขึ้นจะเป็น 0 ซึ่งจะแทนที่อินสแตนซ์ทั้งหมด จำนวนลบจะแทนที่อินสแตนซ์นั้น โดยค้นหาจากจุดสิ้นสุด
=REGEXREPLACE(A1, "\d{3}", "***")
มาสก์ทุกลำดับสามหลัก
ฟังก์ชันเหล่านี้จะล้นหากส่งคืนอาร์เรย์ (เช่น การแยกหลายรายการ)
ตัวอย่างการใช้งานจริงสำหรับผู้ใช้ Excel Power
สมมติว่าคุณมีข้อมูลที่ยุ่งเหยิง ลองใช้ Regex กับสถานการณ์ทั่วไป
ตัวอย่างที่ 1:การตรวจสอบความถูกต้องของที่อยู่อีเมล
คุณสามารถใช้ REGEXTEST เพื่อตั้งค่าสถานะอีเมลบริษัทที่ถูกต้อง (การจับคู่ที่ไม่คำนึงถึงตัวพิมพ์เล็กและใหญ่มักจะปลอดภัยกว่า)
ใช้รูปแบบต่อไปนี้เพื่อตรวจสอบอีเมล
- รูปแบบ: ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$
=REGEXTEST(A2, "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$")
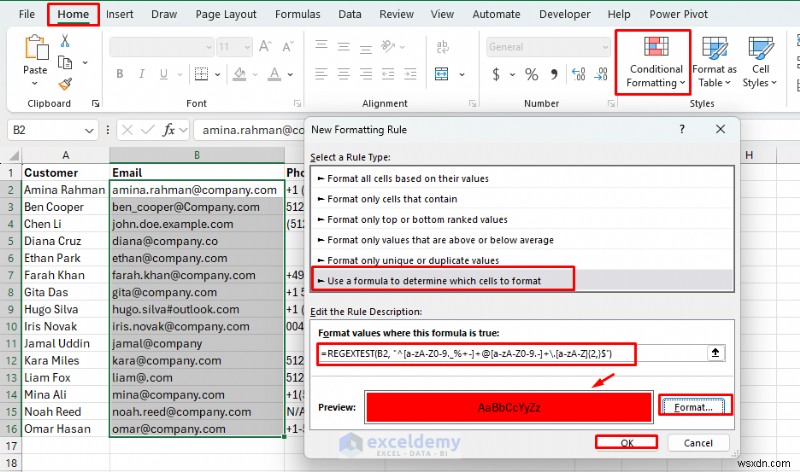
ใช้การจัดรูปแบบตามเงื่อนไขเพื่อเน้นอีเมลที่ไม่ถูกต้อง:
- ไปที่หน้าแรก แท็บ>> เลือก การจัดรูปแบบตามเงื่อนไข>> เลือก กฎใหม่
- เลือก ใช้สูตรเพื่อกำหนดเซลล์ที่จะจัดรูปแบบ
- แทรกสูตรต่อไปนี้
- เลือก รูปแบบ>> เลือกสีเติม>> คลิก ตกลง
- ที่อยู่อีเมลที่ไม่ถูกต้องจะถูกเน้นด้วยสีแดง
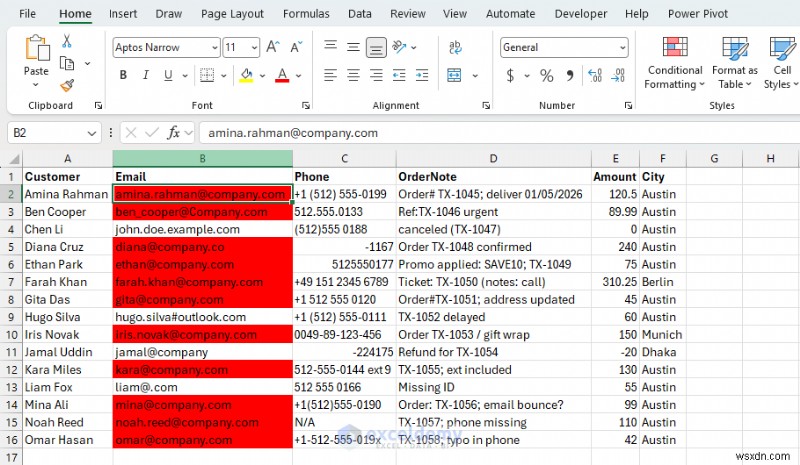
คุณยังสามารถใช้ REGEXTEST เพื่อตั้งค่าสถานะอีเมลบริษัทที่ถูกต้องได้
=REGEXTEST(B2,"@company\.com$",1)
- อาร์กิวเมนต์ที่สาม (1 ) ทำให้การจับคู่ไม่คำนึงถึงตัวพิมพ์เล็กและตัวพิมพ์ใหญ่ ดังนั้น Company.com ยังคงผ่านไป
- \. หนีจุด ธรรมดา . หมายถึง "อักขระใดๆ"
ตัวอย่างที่ 2:การแยกข้อมูลจากบันทึกที่ยุ่งเหยิง
สมมติว่าคุณมีข้อมูลผสม เช่น รหัสคำสั่งซื้อหรือหมายเลขโทรศัพท์ ในบันทึกย่อ คุณสามารถแยกหมายเลขโทรศัพท์หรือรหัสคำสั่งซื้อได้โดยใช้ฟังก์ชัน REGEXEXTRACT
แยกรหัสคำสั่งซื้อ:
=REGEXEXTRACT(D2,"TX-\d{4}")
- หากบางแถวไม่มี ให้ห่อด้วย IFERROR:
=IFERROR(REGEXEXTRACT(D2,"TX-\d{4}"),"")
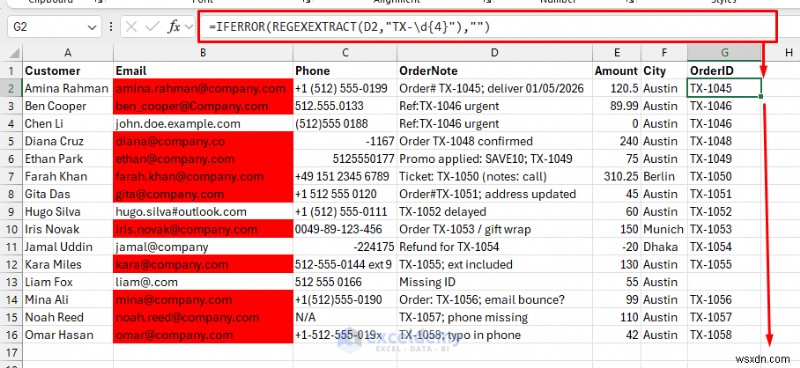
แยกหมายเลขโทรศัพท์:
- ข้อมูล: “โทรหาฉันที่ 123-456-7890 หรือ (987) 654-3210”
- รูปแบบ: (\d{3}[-. )]+){2}\d{4}
=REGEXEXTRACT(A2, "(\d{3}[-. )]+){2}\d{4}", 0, 1)
สูตรนี้จะแยกหมายเลขโทรศัพท์ออกจากข้อความ
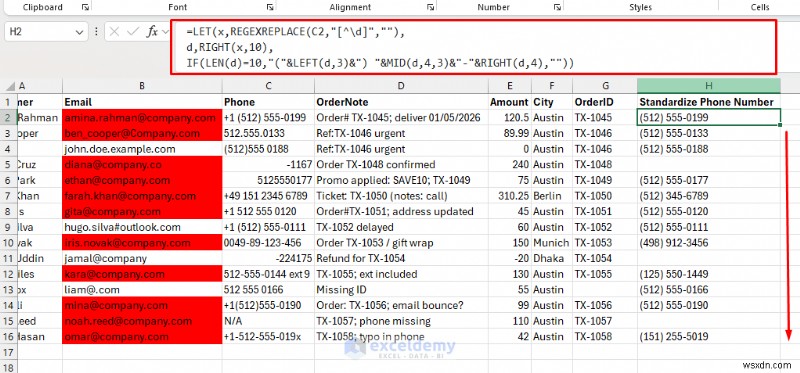
ตัวอย่างที่ 3:การทำให้หมายเลขโทรศัพท์เป็นมาตรฐานโดยการลบตัวเลขที่ไม่ใช่ตัวเลขออก
- สร้างเวอร์ชันเฉพาะตัวเลขก่อน
=REGEXREPLACE(C2,"[^\d]","")
- ขณะนี้ คุณสามารถจัดรูปแบบ (ตัวอย่าง:10 หลักสุดท้ายเป็นหมายเลขสหรัฐอเมริกา หากมี):
=LET(x,REGEXREPLACE(C2,"[^\d]",""),
d,RIGHT(x,10),
IF(LEN(d)=10,"("&LEFT(d,3)&") "&MID(d,4,3)&"-"&RIGHT(d,4),""))
วิธีการนี้จะลบอักขระที่ไม่ใช่ตัวเลขทั้งหมดและจัดรูปแบบหมายเลขโทรศัพท์ที่ได้
ตัวอย่างที่ 4:การแยกวิเคราะห์วันที่และการจัดรูปแบบใหม่
คุณสามารถแยกวิเคราะห์วันที่และจัดรูปแบบใหม่โดยใช้ regex ได้
- รูปแบบ: (\d{1,2})/(\d{1,2})/(\d{4})
=REGEXREPLACE(A2, "(\d{1,2})/(\d{1,2})/(\d{4})", "$3-$2-$1")
สูตรนี้จะแยกวิเคราะห์วันที่แล้วฟอร์แมตใหม่ให้เป็นรูปแบบ ISO ที่ถูกต้อง คุณยังสามารถใช้กลุ่มการจับ () เพื่ออ้างอิงชิ้นส่วนทดแทนได้
ตัวอย่างที่ 5:การทำความสะอาดข้อมูลที่ยุ่งเหยิง (เช่น การลบช่องว่างเพิ่มเติม)
คุณสามารถใช้ regex เพื่อล้างข้อมูลที่ยุ่งเหยิง เช่น การลบช่องว่างเพิ่มเติมและการจัดรูปแบบให้เป็นมาตรฐาน
หากต้องการลบช่องว่างเพิ่มเติม ให้ใช้รูปแบบต่อไปนี้
- รูปแบบ: \s+
=REGEXREPLACE(A2, "\s+", " ")
สูตรนี้แทนที่การเว้นช่องว่างด้วยช่องว่างเดียว
ตัวอย่างที่ 6:การลบสิ่งใดก็ตามที่อยู่ในวงเล็บออก (รวมถึงวงเล็บด้วย)
- เลือกเซลล์และแทรกสูตรต่อไปนี้:
=REGEXREPLACE(D2,"\s*\(.*?\)","")
- .*? เป็นคนไม่โลภ ตรงกัน โดยจะหยุดที่วงเล็บปิดตัวแรกแทนที่จะเป็นวงเล็บสุดท้าย
สูตรนี้จะลบข้อมูลทั้งหมดที่อยู่ในวงเล็บ รวมถึงวงเล็บด้วย
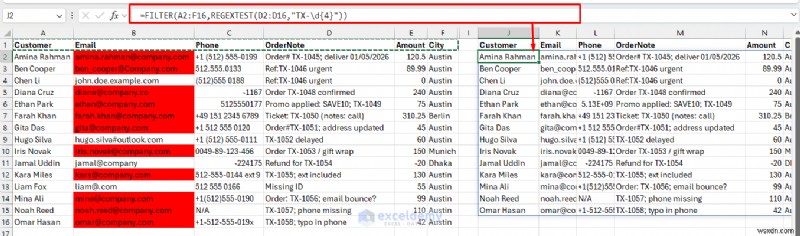
ตัวอย่างที่ 7:การกรองแถวที่มีรหัสคำสั่งซื้อ
=FILTER(A2:F16,REGEXTEST(D2:D16,"TX-\d{4}"))
สูตรนี้จะกรองข้อมูลตามรูปแบบ regex
เทคนิค Regex ขั้นสูงใน Excel
- มองไปข้างหน้า/มองข้างหลัง: ยืนยันเงื่อนไขโดยไม่ต้องใช้ข้อความ
- มองไปข้างหน้าเชิงบวก:(?=…) เช่น \d+(?=%)$ สำหรับตัวเลขก่อนเครื่องหมาย %
- ใช้ใน REGEXEXTRACT เพื่อแยกราคา:\d+\.\d{2}(?=\sUSD)
- กลุ่มที่ไม่จับภาพ: (?:…) สำหรับการจัดกลุ่มโดยไม่ต้องจับภาพ
- ทางเลือก: สำหรับตัวเลือก เช่น (http|https)://\S+ สำหรับ URL
- การจัดการอาร์เรย์: หาก REGEXEXTRACT ส่งคืนหลายกลุ่ม ให้ใช้ INDEX หรือช่วงที่หก
- รวมกับฟังก์ชันอื่นๆ: ซ้อนกับ IF, FILTER หรือ LAMBDA เพื่อขั้นตอนการทำงานที่มีประสิทธิภาพ
เคล็ดลับและแนวทางปฏิบัติที่ดีที่สุด
- รูปแบบการทดสอบ: ใช้เครื่องมือออนไลน์ เช่น regex101.com ที่มีรูปแบบ “ECMAScript” (ใกล้เคียงกับ regex ของ Excel มากที่สุด)
- ประสิทธิภาพ: Regex อาจทำงานช้าในชุดข้อมูลขนาดใหญ่ ทดสอบตัวอย่างก่อน
- ข้อผิดพลาด: หากไม่มีค่าที่ตรงกัน REGEXEXTRACT จะส่งกลับ #N/A; จัดการกับ IFNA หรือ IFERROR
- ข้อจำกัด: Regex ของ Excel ขึ้นอยู่กับชุดย่อย โดยไม่มีการสนับสนุน PCRE เต็มรูปแบบ ดังนั้นควรหลีกเลี่ยงคุณลักษณะขั้นสูง เช่น การเรียกซ้ำ
- การเรียนรู้เพิ่มเติม: ฝึกฝนกับชุดข้อมูลจริง Regex ง่ายขึ้นเมื่อใช้งาน!
ดาวน์โหลดแบบฝึกหัด
สรุป
ผู้ใช้ Excel ระดับสูงสามารถติดตามหลักสูตรข้อขัดข้องของ regex ของเราเพื่อเร่งการล้างข้อมูล การตรวจสอบความถูกต้อง และระบบอัตโนมัติ เมื่อคุณพอใจกับโครงสร้างพื้นฐานแล้ว ให้สำรวจมองไปข้างหน้าและมองข้างหลังเพื่อจับคู่รูปแบบที่ซับซ้อนยิ่งขึ้น หลักสูตรเร่งรัดนี้ช่วยให้คุณเริ่มต้นได้ ขั้นแรกให้เข้าใจสำนวน จากนั้นจึงทดลองกับรูปแบบในสมุดงานเปล่า Regex สามารถเปลี่ยนวิธีจัดการข้อความใน Excel ได้!
รับแบบฝึกหัด Excel ขั้นสูงพร้อมโซลูชันฟรี!