

Excel เป็นเครื่องมือที่เหมาะสำหรับนักวิเคราะห์ข้อมูลจำนวนมาก เนื่องจากความเรียบง่ายและความยืดหยุ่น แต่สำหรับงานข้อมูลขนาดใหญ่ ซ้ำซ้อน หรือซับซ้อน Python มอบความเร็ว ระบบอัตโนมัติ และการวิเคราะห์ขั้นสูง ด้วยการผสานรวม Excel เข้ากับ Python คุณสามารถใช้ประโยชน์จากทั้งสองโลกได้
ในบทช่วยสอนนี้ เราจะแสดงวิธีรวม Excel กับ Python เพื่อเวิร์กโฟลว์วิทยาศาสตร์ข้อมูลที่มีประสิทธิภาพ
เครื่องมือและการตั้งค่าที่จำเป็น
ก่อนที่จะรวม Excel กับ Python ให้ตั้งค่าสภาพแวดล้อม ซึ่งจะทำให้ขั้นตอนการทำงานของคุณราบรื่นและมีประสิทธิภาพตั้งแต่ขั้นตอนแรก
ข้อกำหนดเบื้องต้น:
- ไมโครซอฟต์ เอ็กเซล :สำหรับการตรวจสอบและการรายงานข้อมูลเบื้องต้น
- หลาม 3.x :เครื่องมือสำหรับเวิร์กโฟลว์วิทยาศาสตร์ข้อมูลของคุณ
- ไลบรารี Python :
- แพนด้า สำหรับการวิเคราะห์ข้อมูล
- matplotlib สำหรับการวางแผน
- openpyxl (เป็นทางเลือก สำหรับการเขียนไฟล์ Excel)
- จำนวน (ตัวเลข).
- matplotlib/ท้องทะเล สำหรับการแสดงภาพ
ติดตั้งไลบรารี Python:
pip install pandas matplotlib openpyxl
1. อ่านข้อมูลลงใน Python
คุณสามารถโหลดข้อมูลของคุณลงใน Python โดยใช้แพนด้า ซึ่งทำให้ง่ายต่อการจัดการและวิเคราะห์ข้อมูลแบบตาราง
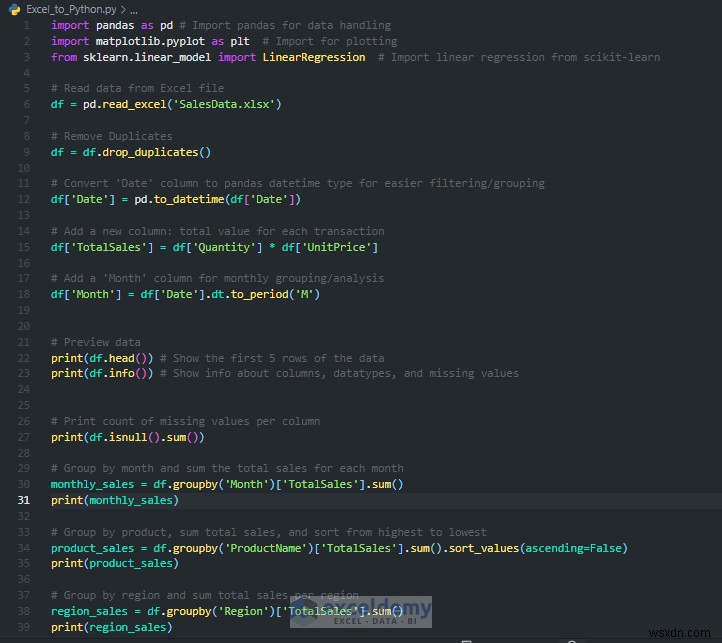
import pandas as pd
# Read data from Excel file
df = pd.read_excel('SalesData.xlsx')
# Preview data
print(df.head()) # Show the first 5 rows of the data
print(df.info()) # Show info about columns, datatypes, and missing values
- pd.read_csv() อ่านไฟล์ Excel ลงใน DataFrame ของแพนด้า
- df.head() แสดงห้าแถวแรก เหมาะสำหรับการตรวจสอบอย่างรวดเร็ว
- df.info() แสดงจำนวนแถว คอลัมน์ และประเภทข้อมูล
คุณจะเห็นข้อมูลการขายสองสามแถวแรก พร้อมด้วยข้อมูลสรุปเช่น:
TransactionID Date CustomerID ProductID ProductName Category Quantity UnitPrice Region Channel SalesRep 0 100001 2024-01-02 C-100 P-101 Laptop Electronics 2.0 800.0 East Online Smith 1 100002 2024-01-02 C-101 P-102 Printer Electronics 1.0 200.0 West Retail Johnson 2 100003 2024-01-03 C-102 P-103 Mouse Electronics 5.0 25.0 North Online Lee 3 100004 2024-01-04 C-103 P-104 Desk Furniture 1.0 150.0 South Retail Brown 4 100005 2024-01-05 C-104 P-105 Monitor Electronics 3.0 175.0 NaN Online Davis <class 'pandas.core.frame.DataFrame'> RangeIndex: 63 entries, 0 to 62 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 TransactionID 63 non-null int64 1 Date 62 non-null datetime64[ns] 2 CustomerID 62 non-null object 3 ProductID 61 non-null object 4 ProductName 63 non-null object 5 Category 61 non-null object 6 Quantity 61 non-null float64 7 UnitPrice 62 non-null float64 8 Region 62 non-null object 9 Channel 62 non-null object 10 SalesRep 62 non-null object dtypes: datetime64[ns](1), float64(2), int64(1), object(7) memory usage: 5.5+ KB None
2. การล้างข้อมูลและการเปลี่ยนแปลง
ข้อมูลดิบไม่ค่อยพร้อมสำหรับการวิเคราะห์ ในขั้นตอนนี้ คุณจะแก้ไขค่าที่หายไป แปลงคอลัมน์ให้เป็นประเภทที่ถูกต้อง และเพิ่มฟิลด์จากการคำนวณใหม่
ลบรายการที่ซ้ำกัน:
# Remove Duplicates df = df.drop_duplicates()
- ปล่อยค่าที่ซ้ำกัน
ตรวจสอบค่าที่หายไป:
# Print count of missing values per column print(df.isnull().sum())
- แสดงจำนวนค่าที่หายไป (NaN) ในแต่ละคอลัมน์ หากพบสิ่งใด คุณสามารถตัดสินใจทิ้งหรือเติมได้
#Output: TransactionID 0 Date 1 CustomerID 1 ProductID 2 ProductName 0 Category 2 Quantity 2 UnitPrice 1 Region 1 Channel 1 SalesRep 1 dtype: int64
แปลงประเภทข้อมูล:
# Convert 'Date' column to pandas datetime type for easier filtering/grouping df['Date'] = pd.to_datetime(df['Date'])
- แปลงคอลัมน์วันที่จากข้อความเป็นรูปแบบวันที่และเวลาของแพนด้าเพื่อการกรองและการจัดกลุ่มที่ง่ายขึ้น
สร้างคอลัมน์ 'ยอดขายรวม':
# Add a new column: total value for each transaction df['TotalSales'] = df['Quantity'] * df['UnitPrice']
- เพิ่มคอลัมน์ใหม่ที่แสดงมูลค่ารวมสำหรับแต่ละธุรกรรม
แยกเดือนสำหรับการวิเคราะห์อนุกรมเวลา:
df['Month'] = df['Date'].dt.to_period('M')
- ซึ่งจะสร้างคอลัมน์เดือนเพื่อจัดกลุ่มและวิเคราะห์ยอดขายตามเดือน
- ตอนนี้ใช้ print(df.head()) เพื่อดูตัวอย่างข้อมูลที่ล้างแล้ว
#Ouput: TransactionID Date CustomerID ProductID ProductName Category ... UnitPrice Region Channel SalesRep TotalSales Month 0 100001 2024-01-02 C-100 P-101 Laptop Electronics ... 800.0 East Online Smith 1600.0 2024-01 1 100002 2024-01-02 C-101 P-102 Printer Electronics ... 200.0 West Retail Johnson 200.0 2024-01 2 100003 2024-01-03 C-102 P-103 Mouse Electronics ... 25.0 North Online Lee 125.0 2024-01 3 100004 2024-01-04 C-103 P-104 Desk Furniture ... 150.0 South Retail Brown 150.0 2024-01 4 100005 2024-01-05 C-104 P-105 Monitor Electronics ... 175.0 NaN Online Davis 525.0 2024-01
3. วิเคราะห์ข้อมูลของคุณ
ด้วยชุดข้อมูลที่สะอาด คุณสามารถสร้างข้อมูลเชิงลึกที่ขับเคลื่อนมูลค่าทางธุรกิจได้แล้ว ซึ่งรวมถึงการรวมยอดขายตามเดือน ผลิตภัณฑ์ และภูมิภาค
ยอดขายรวมตามเดือน:
# Group by month and sum the total sales for each month
monthly_sales = df.groupby('Month')['TotalSales'].sum()
print(monthly_sales)
- จัดกลุ่มข้อมูลตามเดือนและรวมยอดขายรวมในแต่ละเดือน
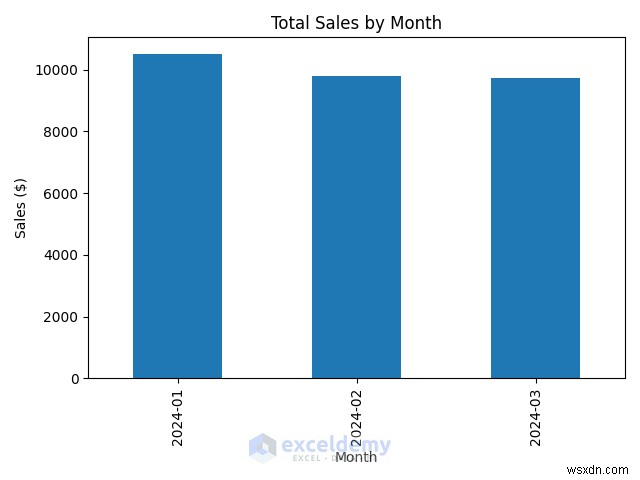
#Output: Month 2024-01 9075.0 2024-02 9800.0 2024-03 9075.0 Freq: M, Name: TotalSales, dtype: float64
ผลิตภัณฑ์ที่ขายดีที่สุด:
# Group by product, sum total sales, and sort from highest to lowest
product_sales = df.groupby('ProductName')['TotalSales'].sum().sort_values(ascending=False)
print(product_sales)
- รวมยอดขายต่อผลิตภัณฑ์ จากนั้นจัดเรียงจากยอดนิยมมากไปน้อย
#Output: ProductName Laptop 15200.0 Monitor 3850.0 Printer 3200.0 Desk 2550.0 Chair 2325.0 Mouse 1125.0 Name: TotalSales, dtype: float64
ยอดขายตามภูมิภาค:
# Group by region and sum total sales per region
region_sales = df.groupby('Region')['TotalSales'].sum()
print(region_sales)
- รวบรวมยอดขายทั้งหมดตามแต่ละภูมิภาค
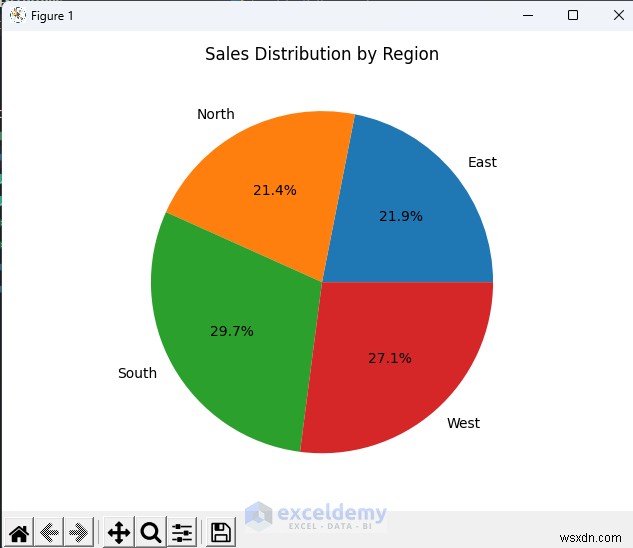
#Output: Region East 6075.0 North 5925.0 South 8225.0 West 7500.0
4. แสดงภาพข้อมูลเชิงลึกที่สำคัญ
ข้อมูลจะมีประสิทธิภาพมากขึ้นเมื่อแสดงภาพ มาสร้างแผนภูมิด่วนเพื่อช่วยให้คุณและผู้มีส่วนได้ส่วนเสียเข้าใจแนวโน้มสำคัญได้อย่างรวดเร็ว
4.1. แนวโน้มยอดขายรายเดือน
import matplotlib.pyplot as plt # Import for plotting
# Create a bar chart of sales by month
monthly_sales.plot(
kind='bar',
title='Total Sales by Month',
ylabel='Sales ($)',
xlabel='Month'
)
plt.tight_layout() # Avoid label overlap
plt.savefig('monthly_sales.png') # Save the figure as a PNG file
plt.show() # Display the chart - แปลงยอดขายรายเดือนเป็นแผนภูมิแท่ง
- plt.savefig บันทึกแผนภูมิสำหรับรายงาน
- แผนภูมิแท่งจะแสดงการเปลี่ยนแปลงยอดขายในแต่ละเดือน
4.2. ยอดขายตามภูมิภาค
# Pie chart of sales by region
region_sales.plot(
kind='pie',
autopct='%1.1f%%',
title='Sales Distribution by Region'
)
plt.ylabel('') # Remove default y-label
plt.tight_layout()
plt.savefig('region_sales.png')
plt.show()
- แผนภูมิวงกลมของยอดขายตามภูมิภาค เหมาะสำหรับการจัดการหรือการตลาด
5. การวิเคราะห์และการสร้างแบบจำลองขั้นสูง
นอกเหนือจากการจัดกลุ่มและการสรุปขั้นพื้นฐานแล้ว Python ยังเปิดใช้งานการวิเคราะห์ทางสถิติขั้นสูง ตาราง Pivot และแม้แต่การเรียนรู้ของเครื่อง ทั้งหมดนี้ทำได้โดยใช้โค้ดเพียงไม่กี่บรรทัด มาเจาะลึกข้อมูลเพื่อปลดล็อกข้อมูลเชิงลึกเพิ่มเติมกัน
5.1. สถิติเชิงพรรณนา
สถิติเชิงพรรณนาช่วยให้คุณสรุปชุดข้อมูลของคุณโดยสรุป โดยแสดงค่าเฉลี่ย ส่วนเบี่ยงเบนมาตรฐาน และควอนไทล์สำหรับคอลัมน์ตัวเลข
# Show summary statistics for numeric columns (mean, std, min, max, quartiles, etc.) print(df.describe())
- df.describe() สรุปคอลัมน์ตัวเลขทั้งหมดอย่างรวดเร็ว (เช่น ปริมาณ ราคาต่อหน่วย TotalSales)
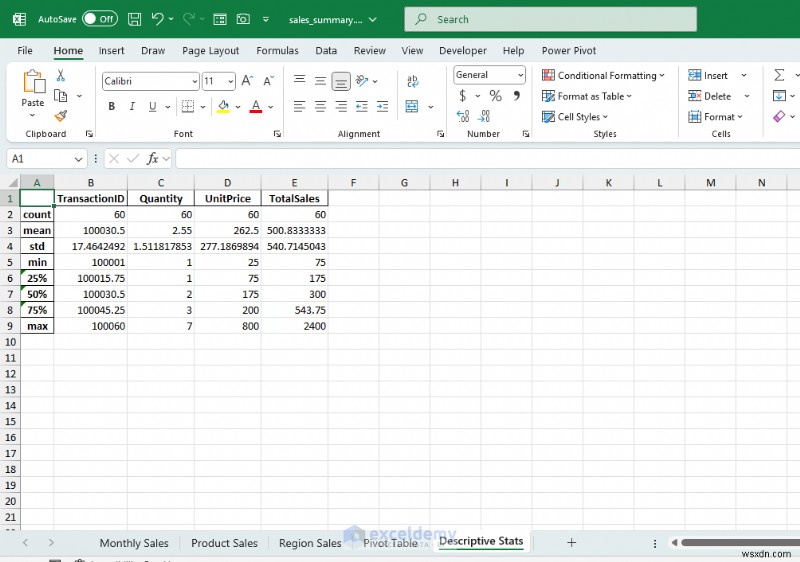
#Output: TransactionID Quantity UnitPrice TotalSales count 61.000000 59.000000 60.000000 59.000000 mean 100030.180328 2.542373 262.083333 478.813559 std 17.497150 1.534905 277.339497 527.085627 min 100001.000000 1.000000 25.000000 75.000000 25% 100015.000000 1.000000 75.000000 162.500000 50% 100030.000000 2.000000 175.000000 300.000000 75% 100045.000000 3.000000 200.000000 525.000000 max 100060.000000 7.000000 800.000000 2400.000000
5.2. ตาราง Pivot ในหมีแพนด้า
ตาราง Pivot มีประสิทธิภาพสำหรับการรายงานเชิงโต้ตอบใน Excel และแพนด้าก็ทำได้เช่นกัน
# Create a pivot table: sum TotalSales for each Region pivot = df.pivot_table(index='Region', values='TotalSales', aggfunc='sum') print(pivot)
- pivot_table() สรุป TotalSales สำหรับแต่ละภูมิภาค คล้ายกับ Pivot Table ของ Excel
#Output TotalSales Region East 6075.0 North 5925.0 South 8225.0 West 7500.0
5.3. ตัวอย่างแมชชีนเลิร์นนิงอย่างง่าย
มาดูกันว่าเราสามารถคาดการณ์ยอดขายรวมจากปริมาณที่ขายโดยใช้แบบจำลองการถดถอยเชิงเส้นอย่างง่าย (การเรียนรู้ของเครื่อง) ได้หรือไม่
from sklearn.linear_model import LinearRegression # Import linear regression from scikit-learn
# Prepare features and target variable
X = df[['Quantity']] # Feature: Quantity sold
y = df['TotalSales'] # Target: Total sales value
# Create and fit the regression model
model = LinearRegression()
model.fit(X, y)
# Print the regression coefficient (slope)
print('Coefficient:', model.coef_)
# Print the intercept (base value when Quantity=0)
print('Intercept:', model.intercept_) - นำเข้า LinearRegression จาก scikit-learn
- ใช้ปริมาณเพื่อคาดการณ์ยอดขายทั้งหมด
- เหมาะกับรุ่นและพิมพ์ค่าสัมประสิทธิ์ (ยอดขายเพิ่มขึ้นต่อหน่วยที่ขายเพิ่ม)
#Output: Coefficient: [-37.65294772] Intercept: 596.8483500185391
6. ส่งออกข้อมูลที่ล้าง/วิเคราะห์แล้วกลับไปยัง Excel
หลังจากทำความสะอาด วิเคราะห์ และจำลองข้อมูลของคุณแล้ว คุณสามารถส่งออกตารางสรุปและข้อมูลเชิงลึกไปยังไฟล์ Excel แบบหลายชีตได้ ซึ่งจะช่วยรวบรวมการค้นพบที่สำคัญทั้งหมดของคุณไว้ด้วยกันและพร้อมสำหรับการตรวจสอบใน Excel
# Export summary and advanced analysis tables to a multi-sheet Excel file
with pd.ExcelWriter('sales_summary.xlsx') as writer:
# Monthly summary
monthly_sales.to_frame().to_excel(writer, sheet_name='Monthly Sales')
# Product summary
product_sales.to_frame().to_excel(writer, sheet_name='Product Sales')
# Region summary
region_sales.to_frame().to_excel(writer, sheet_name='Region Sales')
# Pivot table (total sales by region)
pivot.to_excel(writer, sheet_name='Pivot Table')
# Optionally, you can export descriptive statistics
df.describe().to_excel(writer, sheet_name='Descriptive Stats')
- เครื่องมือจัดการบริบท (โดยมี … เป็นผู้เขียน): ตรวจสอบให้แน่ใจว่าไฟล์ Excel ได้รับการบันทึกและปิดอย่างถูกต้องหลังจากเขียน
- .to_excel() สำหรับแต่ละตาราง: บันทึก DataFrame แต่ละรายการหรือสรุปลงในชีตของตัวเองเพื่อให้เข้าถึงได้ง่าย
- ชื่อแผ่นงานที่กำหนดเอง: แต่ละชีตได้รับการตั้งชื่อเพื่อความชัดเจนซึ่งตรงกับขั้นตอนการวิเคราะห์ของคุณ
- เปิด sales_summary.xlsx ใน Excel
- คุณจะเห็นชีตแยกต่างหากสำหรับยอดขายรายเดือน ยอดขายผลิตภัณฑ์ การขายในภูมิภาค ตาราง Pivot และสถิติเชิงพรรณนา
7. อัตโนมัติและปรับขนาดขั้นตอนการทำงานของคุณ
ด้วยการใช้ Python คุณสามารถจัดทำรายงานหรือการวิเคราะห์ที่เกิดซ้ำได้โดยอัตโนมัติ ครั้งต่อไปที่คุณได้รับไฟล์ Excel ใหม่ เพียงแทนที่ไฟล์และรันสคริปต์ของคุณใหม่ การวิเคราะห์และรายงานทั้งหมดจะถูกรีเฟรชทันที
- เก็บโค้ดการวิเคราะห์ทั้งหมดไว้ในไฟล์ Python ไฟล์เดียว
- หากต้องการอัปเดตรายงานของคุณ ให้แทนที่ CSV และเรียกใช้:
python Excel_to_Python.py
- หากต้องการประสิทธิภาพที่มากยิ่งขึ้น คุณสามารถกำหนดเวลานี้เป็นงานรายสัปดาห์/รายเดือนได้
บทสรุป
ด้วยการรวมการป้อนข้อมูลและการรายงานที่ใช้งานง่ายของ Excel เข้ากับพลังด้านวิทยาศาสตร์ข้อมูลของ Python คุณสามารถประมวลผลและวิเคราะห์ชุดข้อมูลขนาดใหญ่ที่ยุ่งเหยิงได้อย่างมีประสิทธิภาพ มันทำให้งานการรายงานซ้ำ ๆ โดยอัตโนมัติ ปลดล็อกการเรียนรู้ของเครื่องและการแสดงภาพขั้นสูง คุณไม่จำเป็นต้องเป็นผู้เชี่ยวชาญ Python เพียงชั่วข้ามคืน เริ่มต้นด้วยงานง่ายๆ งานเดียว เมื่อได้ผลแล้ว ให้เพิ่มอีกหนึ่งขั้นตอน ก่อนที่คุณจะรู้ตัว คุณจะสร้างรายงานที่ซับซ้อนโดยอัตโนมัติ
รับแบบฝึกหัด Excel ขั้นสูงพร้อมโซลูชันฟรี!