
เรามีความยินดีที่จะประกาศเปิดตัวก้าวแรกในการพัฒนา RediSearch 2.0 RediSearch เป็นเสิร์ชเอ็นจิ้นแบบเรียลไทม์ที่ให้คุณสืบค้นข้อมูล Redis ของคุณเพื่อตอบคำถามที่ซับซ้อนหลากหลาย
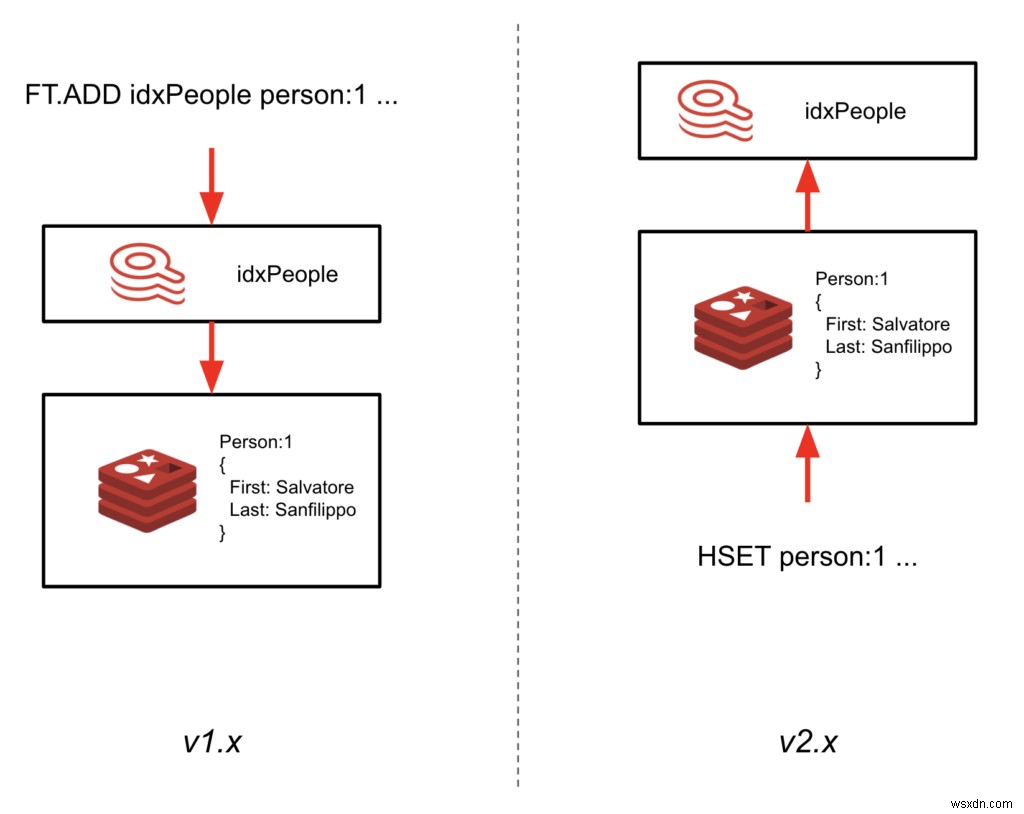
เหตุการณ์สำคัญนี้เรียกว่า 2.0-M01 นับเป็นการสร้างโครงสร้างใหม่ของวิธีที่ดัชนีถูกซิงค์กับข้อมูล แทนที่จะต้องเขียนข้อมูลผ่านดัชนี (โดยใช้ FT.ADD คำสั่ง) RediSearch จะติดตามข้อมูลที่เขียนในแฮชและจัดทำดัชนีโดยอัตโนมัติ
ข้อได้เปรียบที่สำคัญคือตอนนี้คุณสามารถเพิ่ม RediSearch ให้กับอินสแตนซ์ Redis ที่มีอยู่และสร้างดัชนีรองโดยไม่ต้องอัปเดตโค้ดแอปพลิเคชันของคุณ วิธีนี้ช่วยให้คุณเริ่มใช้ RediSearch กับข้อมูลที่มีอยู่ได้ทันที เพียงโหลดโมดูล RediSearch และกำหนดสคีมา คาดว่าจะพร้อมใช้งานทั่วไปของ RediSearch 2.0 ในฤดูใบไม้ร่วงนี้
(หมายเหตุ: คุณลักษณะใหม่นี้แนะนำการเปลี่ยนแปลงบางอย่างใน API (รายการด้านล่าง) เราพยายามรักษาความเข้ากันได้แบบย้อนหลังให้มากที่สุด แต่ในกรณีนี้ เป็นไปไม่ได้ เราวางแผนที่จะทำการปรับเปลี่ยนและแก้ไขต่อไปเมื่อเรารวบรวมความคิดเห็นของลูกค้า)
การเปลี่ยนแปลง API
ตามที่ระบุไว้ข้างต้น เป้าหมาย RediSearch 2.0 นี้มีการเปลี่ยนแปลงหลายอย่างใน API:
- ดัชนีไม่อยู่ในพื้นที่คีย์อีกต่อไป หากคุณใช้คีย์ดัชนี (idx:<ชื่อดัชนี>) เพื่อแสดงรายการดัชนีในฐานข้อมูล ตัวอย่างเช่น วิธีนี้ใช้ไม่ได้อีกต่อไป อย่างไรก็ตาม เราได้แนะนำคำสั่ง FT._LIST เพื่อส่งคืนดัชนีทั้งหมดในฐานข้อมูล
- ต้องสร้างดัชนีด้วยคำนำหน้า/ตัวกรอง ซึ่งระบุเอกสารที่จะจัดทำดัชนีโดยอัตโนมัติโดย RediSearch คุณสามารถระบุคำนำหน้าอย่างง่ายและ/หรือนิพจน์ตัวกรองที่ซับซ้อนได้
- ไม่สามารถอัพเกรดได้ หากคุณมี RDB ที่สร้างด้วย RediSearch เวอร์ชันเก่า RediSearch 2.0 จะไม่สามารถอ่านได้ ปัจจุบัน คุณจะต้องสร้างดัชนีใหม่ทั้งชุดข้อมูล อย่างไรก็ตาม เรากำลังดำเนินการอัปเกรดสำหรับรุ่น GA
- ใช้งานได้กับ Redis 6 ขึ้นไปเท่านั้น
- คำสั่ง FT ถูกแมปกับคำสั่งที่เทียบเท่า Redis ซึ่งช่วยให้แอปพลิเคชันที่มีอยู่ยังคงทำงานกับ RediSearch 2.0 ได้ การทำแผนที่มีดังนี้:
- FT.ADD => HSET
- FT.DEL => DEL (DD โดยค่าเริ่มต้น)
- FT.GET => HGETALL
- FT.MGET => HGETALL
- ดัชนีกลับหัวจะไม่ถูกบันทึกลงใน RDB อีกต่อไป . นี่ไม่ได้หมายความว่าไม่รองรับการคงอยู่ RediSearch จะบันทึกการกำหนดดัชนีไปยัง RDB และจัดทำดัชนีข้อมูลในพื้นหลังหลังจากที่ Redis เริ่มทำงาน คุณสามารถทราบได้ว่าการจัดทำดัชนีใหม่เสร็จสิ้นเมื่อใดโดยการตรวจสอบสถานะการทำดัชนีโดยใช้ FT.INFO คำสั่ง
API ใหม่
การอัปเดตที่ใหญ่ที่สุดสำหรับ API คือวิธีการสร้างดัชนี ใน RediSearch 2.0 คำสั่ง FT.CREATE ใช้ในการสร้างดัชนี ส่วนเพิ่มเติมของ API จะถูกเน้นด้วยสีเหลืองที่นี่:
FT.CREATE {index}
ON {structure}
[PREFIX {count} {prefix} [{prefix} ..]
[FILTER {filter}]
[LANGUAGE_FIELD {lang_field}]
[LANGUAGE {lang}]
[SCORE_FIELD {score_field}]
[SCORE {score}]
[PAYLOAD_FIELD {payload_field}]
[TEMPORARY {seconds}]
[MAXTEXTFIELDS]
[NOOFFSETS] [NOHL] [NOFIELDS] [NOFREQS]
[STOPWORDS {num} {stopword} ...]
SCHEMA {field} [TEXT [NOSTEM] [WEIGHT {weight}] [PHONETIC {matcher}] | NUMERIC | GEO | TAG [SEPARATOR {sep}] ] [SORTABLE][NOINDEX] ... มาดูรายละเอียดกัน:
- เปิด {โครงสร้าง} ปัจจุบันรองรับเฉพาะ HASH
- คำนำหน้า {จำนวน} {คำนำหน้า} บอกดัชนีว่าควรจัดทำดัชนีคีย์ใด คุณสามารถเพิ่มคำนำหน้าหลายรายการเพื่อสร้างดัชนี เนื่องจากอาร์กิวเมนต์เป็นทางเลือก ค่าเริ่มต้นคือ * (คีย์ทั้งหมด)
- ตัวกรอง {ตัวกรอง} เป็นนิพจน์ตัวกรองที่มีภาษานิพจน์การรวม RediSearch แบบเต็ม เป็นไปได้ที่จะใช้ @__key เพื่อเข้าถึงคีย์ที่เพิ่งเพิ่ม/เปลี่ยนแปลง
- ภาษา และ คะแนน ให้คุณแทนที่ภาษาเริ่มต้นและคะแนนสำหรับเอกสารทั้งหมดที่จัดทำดัชนี
- LANGUAGE_FIELD , SCORE_FIELD และ PAYLOAD_FIELD ช่วยให้คุณมีภาษาและการให้คะแนนเฉพาะเอกสาร และใช้เพย์โหลดเป็นฟิลด์ภายในเอกสารได้
ข้อจำกัดและการเปลี่ยนแปลงอื่นๆ
หลักชัยของ RediSearch 2.0-M01 ยังมีการอัปเดตอื่นๆ อีกสองสามอย่าง:
- NOSAVE ไม่รองรับอีกต่อไป
- การอัปเดตแฮชหมายความว่าเอกสารทั้งหมดจะได้รับการจัดทำดัชนี (การแจ้งเตือนคีย์สเปซไม่ได้ระบุว่าฟิลด์ใดมีการเปลี่ยนแปลง) ดังนั้นการอัปเดตบางส่วนจะช้าลง โปรดทราบว่าเรายังคงตรวจสอบตัวเลือกต่างๆ เพื่อปรับปรุงประสิทธิภาพในสถานการณ์เหล่านี้
- ตอนนี้ชื่อช่องต้องคำนึงถึงตัวพิมพ์เล็กและตัวพิมพ์ใหญ่ ดังนั้นการประกาศช่อง "FOO" และการสร้างดัชนีเป็น "foo" จะไม่ทำงาน
- The FT.ADD คำสั่งจะถูกแมปกับ hset ดังที่แสดงไว้ที่นี่:
FT.ADD idx doc1 1.0 LANGUAGE eng PAYLOAD payload FIELDS f1 v1 f2 v2
ถูกแมปกับ
HSET doc1 __score 1.0 __language eng __payload payload f1 v1 f2 v2
ซึ่งหมายความว่าฟิลด์คะแนน ภาษา และเพย์โหลดบนดัชนีของคุณต้องเรียกว่า __score, __language, __payload เพื่อให้การแมปทำงานตามที่คาดไว้
- FT.ADDHASH ไม่ได้รับการสนับสนุนอีกต่อไป ใช้ HSET .
- FT.OPTIMIZE ไม่รองรับอีกต่อไป ฟังก์ชัน RediSearch Garbage Collection มีหน้าที่ปรับดัชนีให้เหมาะสม
บทสรุป
เรารู้สึกตื่นเต้นมากเกี่ยวกับการเปลี่ยนแปลงเหล่านี้ เนื่องจากขณะนี้คุณสามารถโหลด RediSearch ลงในฐานข้อมูล Redis ที่มีอยู่และจัดทำดัชนีข้อมูลที่มีอยู่ของคุณซึ่งอยู่ในแฮช โดยไม่ต้องอัปเดตตรรกะของแอปพลิเคชันของคุณเมื่อจัดการกับเอกสารเหล่านี้ คุณสามารถทดลองใช้งานหลักสำคัญนี้ได้โดยใช้ซอร์สโค้ดจาก GitHub หรือโดยใช้ 1:99:1 อิมเมจ RedisSarch Docker เวอร์ชันนี้ยังไม่พร้อมสำหรับการผลิต แต่เราต้องการแชร์กับคุณตอนนี้เพื่อรวบรวมความคิดเห็นของคุณ โปรดแบ่งปันความคิดเห็นหรือปัญหาใดๆ บนที่เก็บ GitHub ของเราหรือในฟอรัมชุมชน Redis
