
RedisTimeSeries เป็นโมดูล Redis ที่นำโครงสร้างข้อมูลอนุกรมเวลาดั้งเดิมมาสู่ Redis โซลูชันอนุกรมเวลาซึ่งสร้างขึ้นก่อนหน้านี้บนชุดการจัดเรียง (หรือ Redis Streams) จะได้รับประโยชน์จากคุณลักษณะของ RedisTimeSeries เช่น การแทรกปริมาณมาก การอ่านที่มีความหน่วงต่ำ ภาษาการสืบค้นที่ยืดหยุ่น การสุ่มตัวอย่างข้อมูล และอื่นๆ อีกมากมาย!
โดยทั่วไป ข้อมูลอนุกรมเวลา (ค่อนข้างง่าย) ที่กล่าวว่าเราต้องคำนึงถึงลักษณะอื่นๆ ด้วย:
- ความเร็วของข้อมูล:เช่น นึกถึงเมตริกนับร้อยจากอุปกรณ์นับพันต่อวินาที
- ปริมาณ (บิ๊กดาต้า):คิดว่าการสะสมข้อมูลในช่วงหลายเดือน (หรือหลายปี)
ดังนั้น ฐานข้อมูลเช่น RedisTimeSeries เป็นเพียงส่วนหนึ่งของโซลูชันโดยรวม คุณต้องคิดเกี่ยวกับวิธีการ รวบรวม (นำเข้า) กระบวนการ และ ส่ง ข้อมูลทั้งหมดของคุณไปยัง RedisTimeSeries สิ่งที่คุณต้องการจริงๆ คือไปป์ไลน์ข้อมูลที่ปรับขนาดได้ซึ่งทำหน้าที่เป็นบัฟเฟอร์เพื่อแยกผู้ผลิตและผู้บริโภคออก
นั่นคือที่มาของ Apache Kafka! นอกจากโบรกเกอร์หลักแล้ว ยังมีระบบนิเวศของส่วนประกอบต่างๆ มากมาย รวมถึง Kafka Connect (ซึ่งเป็นส่วนหนึ่งของสถาปัตยกรรมโซลูชันที่นำเสนอในโพสต์บล็อกนี้) ไลบรารีไคลเอ็นต์ในหลายภาษา Kafka Streams, Mirror Maker ฯลฯ
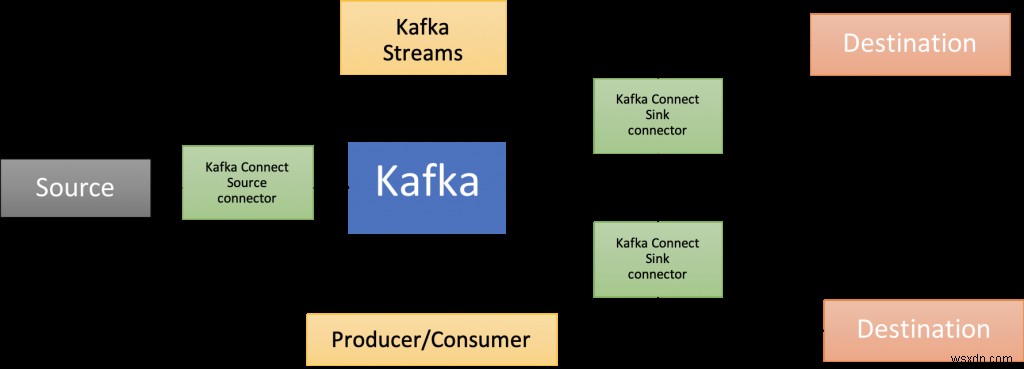
โพสต์ในบล็อกนี้แสดงตัวอย่างการใช้งาน RedisTimeSeries กับ Apache Kafka ในการวิเคราะห์ข้อมูลอนุกรมเวลา
รหัสมีอยู่ใน repo GitHub นี้ https://github.com/abhirockzz/redis-timeseries-kafka
เริ่มต้นด้วยการสำรวจกรณีการใช้งานก่อน โปรดทราบว่ามันถูกเก็บไว้อย่างเรียบง่ายเพื่อจุดประสงค์ในการโพสต์บล็อกและจะอธิบายเพิ่มเติมในหัวข้อต่อๆ ไป
สถานการณ์:การตรวจสอบอุปกรณ์
ลองนึกภาพว่ามีสถานที่หลายแห่ง แต่ละแห่งมีอุปกรณ์หลายเครื่อง และคุณได้รับมอบหมายให้รับผิดชอบในการตรวจสอบเมตริกของอุปกรณ์ สำหรับตอนนี้ เราจะพิจารณาอุณหภูมิและความดัน เมทริกเหล่านี้จะถูกเก็บไว้ใน RedisTimeSeries (แน่นอน!) และใช้หลักการตั้งชื่อต่อไปนี้สำหรับคีย์—
ต่อไปนี้คือตัวอย่างสองสามตัวอย่างเพื่อให้คุณทราบว่าคุณจะเพิ่มจุดข้อมูลโดยใช้คำสั่ง TS.ADD ได้อย่างไร:
# อุณหภูมิสำหรับอุปกรณ์ 2 ในตำแหน่ง 3 พร้อมป้ายกำกับ:
TS.ADD temp:3:2 * 20 LABELS metric temp location 3 device 2
# ความกดดันสำหรับอุปกรณ์ 2 ในตำแหน่ง 3:
TS.ADD pressure:3:2 * 60 LABELS metric pressure location 3 device 2
สถาปัตยกรรมโซลูชัน
นี่คือลักษณะของโซลูชันในระดับสูง:
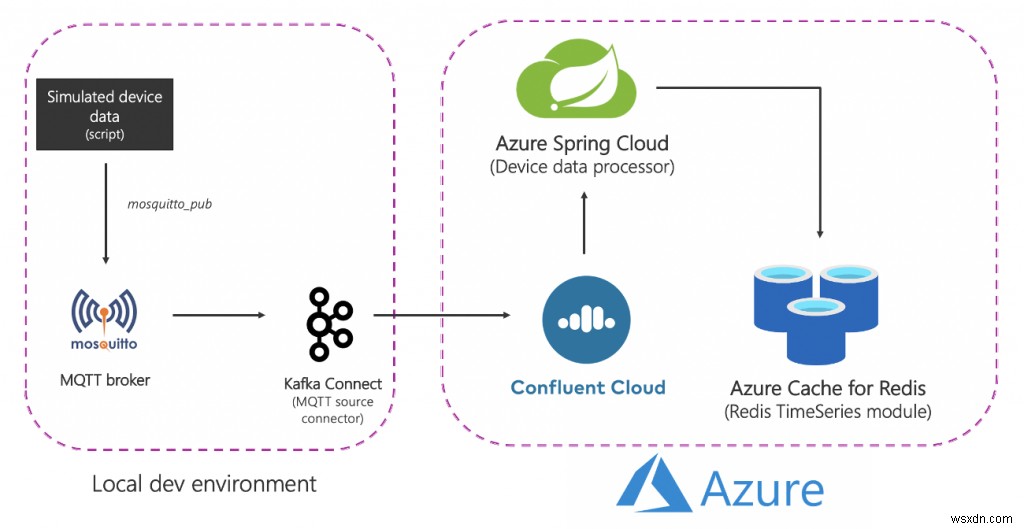
มาทำลายมันกันเถอะ:
แหล่งที่มา (ท้องถิ่น) ส่วนประกอบ
- โบรกเกอร์ MQTT (ยุง): MQTT เป็นโปรโตคอลตามความเป็นจริงสำหรับกรณีการใช้งาน IoT สถานการณ์ที่เราจะใช้คือการรวมกันของ IoT และ Time Series – เพิ่มเติมเกี่ยวกับเรื่องนี้ในภายหลัง
- Kafka Connect:เครื่องมือเชื่อมต่อต้นทาง MQTT ใช้เพื่อถ่ายโอนข้อมูลจากโบรกเกอร์ MQTT ไปยังคลัสเตอร์ Kafka
บริการ Azure
- Azure Cache สำหรับระดับ Redis Enterprise:ระดับ Enterprise นั้นอิงจาก Redis Enterprise ซึ่งเป็นตัวแปรทางการค้าของ Redis จาก Redis นอกจาก RedisTimeSeries แล้ว ระดับองค์กรยังรองรับ RediSearch และ RedisBloom ลูกค้าไม่ต้องกังวลกับการได้มาซึ่งใบอนุญาตสำหรับระดับองค์กร Azure Cache for Redis จะอำนวยความสะดวกในกระบวนการนี้ โดยลูกค้าสามารถรับและชำระค่าใบอนุญาตสำหรับซอฟต์แวร์นี้ผ่านข้อเสนอ Azure Marketplace
- Confluence Cloud on Azure:ข้อเสนอที่มีการจัดการเต็มรูปแบบซึ่งให้บริการ Apache Kafka ด้วยเลเยอร์การจัดเตรียมที่ผสานรวมจาก Azure ไปจนถึง Confluent Cloud ช่วยลดภาระของการจัดการข้ามแพลตฟอร์มและมอบประสบการณ์การใช้งานแบบรวมสำหรับการใช้โครงสร้างพื้นฐาน Confluence Cloud บน Azure ซึ่งจะทำให้คุณสามารถผสานรวม Confluent Cloud กับแอปพลิเคชัน Azure ของคุณได้อย่างง่ายดาย
- Azure Spring Cloud: การปรับใช้ไมโครเซอร์วิส Spring Boot กับ Azure นั้นง่ายขึ้นด้วย Azure Spring Cloud Azure Spring Cloud บรรเทาข้อกังวลด้านโครงสร้างพื้นฐาน ให้การจัดการการกำหนดค่า การค้นพบบริการ การรวม CI/CD การปรับใช้สีน้ำเงิน-เขียว และอื่นๆ บริการนี้ทำงานอย่างหนักเพื่อให้นักพัฒนาสามารถมุ่งเน้นไปที่โค้ดของตนได้
โปรดทราบว่าบริการบางอย่างถูกโฮสต์ในเครื่องเพื่อให้ทุกอย่างง่ายขึ้น ในการปรับใช้เกรดการผลิต คุณจะต้องการเรียกใช้ใน Azure เช่นกัน ตัวอย่างเช่น คุณสามารถใช้งานคลัสเตอร์ Kafka Connect พร้อมกับตัวเชื่อมต่อ MQTT ใน Azure Kubernetes Service
สรุป นี่คือขั้นตอนตั้งแต่ต้นจนจบ:
- สคริปต์สร้างข้อมูลอุปกรณ์จำลองที่ส่งไปยังโบรกเกอร์ MQTT ในเครื่อง
- ข้อมูลนี้ได้รับจากตัวเชื่อมต่อต้นทางของ MQTT Kafka Connect และส่งไปยังหัวข้อในคลัสเตอร์ Confluent Cloud Kafka ที่ทำงานใน Azure
- มันถูกประมวลผลเพิ่มเติมโดยแอปพลิเคชัน Spring Boot ที่โฮสต์ใน Azure Spring Cloud ซึ่งจะคงอยู่ในอินสแตนซ์ Azure Cache สำหรับ Redis
ได้เวลาเริ่มต้นใช้งานจริงแล้ว! ก่อนหน้านั้น ตรวจสอบให้แน่ใจว่าคุณมีสิ่งต่อไปนี้
ข้อกำหนดเบื้องต้น:
- บัญชี Azure — คุณสามารถรับได้ฟรีที่นี่
- ติดตั้ง Azure CLI
- JDK 11 สำหรับเช่น OpenJDK
- เวอร์ชันล่าสุดของ Maven และ Git
ตั้งค่าส่วนประกอบโครงสร้างพื้นฐาน
ทำตามเอกสารเพื่อจัดเตรียม Azure Cache for Redis (ระดับองค์กร) ซึ่งมาพร้อมกับโมดูล RedisTimeSeries
จัดเตรียมคลัสเตอร์ Confluence Cloud บน Azure Marketplace สร้างหัวข้อ Kafka (ใช้ชื่อ mqtt.device-stats) and create credentials (API key and secret) that you will use later on to connect to your cluster securely.

คุณจัดเตรียมอินสแตนซ์ของ Azure Spring Cloud ได้โดยใช้พอร์ทัล Azure หรือใช้ Azure CLI:
az spring-cloud create -n <name of Azure Spring Cloud service> -g <resource group name> -l <enter location e.g southeastasia>
ก่อนดำเนินการต่อ อย่าลืมโคลน GitHub repo:
git clone https://github.com/abhirockzz/redis-timeseries-kafka
cd redis-timeseries-kafkaตั้งค่าบริการในพื้นที่
ส่วนประกอบต่างๆ ได้แก่:
- นายหน้า Mosquitto MQTT
- Kafka เชื่อมต่อกับตัวเชื่อมต่อแหล่ง MQTT
- Grafana สำหรับติดตามข้อมูลอนุกรมเวลาในแดชบอร์ด
โบรกเกอร์ MQTT
ฉันติดตั้งและเริ่มต้นนายหน้ายุงในเครื่อง Mac
brew install mosquitto
brew services start mosquittoคุณสามารถทำตามขั้นตอนที่เกี่ยวข้องกับระบบปฏิบัติการของคุณหรือใช้อิมเมจ Docker ได้ตามสบาย
กราฟาน่า
ฉันติดตั้งและเริ่ม Grafana ในเครื่อง Mac
brew install grafana
brew services start grafanaคุณทำเช่นเดียวกันกับระบบปฏิบัติการหรือใช้อิมเมจ Docker ได้ตามสบาย
docker run -d -p 3000:3000 --name=grafana -e "GF_INSTALL_PLUGINS=redis-datasource" grafana/grafanaKafka Connect
คุณควรจะสามารถค้นหาไฟล์ connect-distributed.properties ใน repo ที่คุณเพิ่งโคลนได้ แทนที่ค่าสำหรับคุณสมบัติ เช่น bootstrap.servers, sasl.jaas.config เป็นต้น
ขั้นแรก ดาวน์โหลดและเปิดเครื่องรูด Apache Kafka ในเครื่อง
เริ่มคลัสเตอร์ Kafka Connect ในเครื่อง:
export KAFKA_INSTALL_DIR=<kafka installation directory e.g. /home/foo/kafka_2.12-2.5.0>
$KAFKA_INSTALL_DIR/bin/connect-distributed.sh connect-distributed.propertiesในการติดตั้งตัวเชื่อมต่อแหล่ง MQTT ด้วยตนเอง:
- ดาวน์โหลดไฟล์ ZIP ของตัวเชื่อมต่อ/ปลั๊กอินจากลิงก์นี้ และ
- แตกไฟล์ลงในไดเร็กทอรีที่ระบุไว้ในคุณสมบัติการกำหนดค่า plugin.path ของผู้ปฏิบัติงาน Connect
หากคุณใช้ Confluence Platform ในเครื่อง เพียงใช้ Confluence Hub CLI: confluent-hub install confluentinc/kafka-connect-mqtt:latest
สร้างอินสแตนซ์ตัวเชื่อมต่อต้นทาง MQTT
ตรวจสอบให้แน่ใจว่าได้ตรวจสอบไฟล์ mqtt-source-config.json ตรวจสอบให้แน่ใจว่าคุณป้อนชื่อหัวข้อที่ถูกต้องสำหรับ kafka.topic และปล่อยให้ mqtt.topics ไม่เปลี่ยนแปลง
curl -X POST -H 'Content-Type: application/json'
http://localhost:8083/connectors -d @mqtt-source-config.json
# wait for a minute before checking the connector status
curl http://localhost:8083/connectors/mqtt-source/statusปรับใช้แอปพลิเคชันตัวประมวลผลข้อมูลอุปกรณ์
ใน GitHub repo ที่คุณเพิ่งโคลน ให้มองหาไฟล์ application.yaml ในโฟลเดอร์ consumer/src/resources folder and replace the values for:
- Azure Cache สำหรับโฮสต์ Redis พอร์ต และคีย์การเข้าถึงหลัก
- ระบบคลาวด์ที่ผสานกันบนคีย์และข้อมูลลับของ Azure API
สร้างไฟล์ JAR ของแอปพลิเคชัน:
cd consumer
export JAVA_HOME=<enter absolute path e.g. /Library/Java/JavaVirtualMachines/zulu-11.jdk/Contents/Home>
mvn clean packageสร้างแอปพลิเคชัน Azure Spring Cloud และปรับใช้ไฟล์ JAR:
az spring-cloud app create -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group> --runtime-version Java_11
az spring-cloud app deploy -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group> --jar-path target/device-data-processor-0.0.1-SNAPSHOT.jarเริ่มเครื่องจำลองข้อมูลอุปกรณ์จำลอง
คุณสามารถใช้สคริปต์ใน GitHub repo ที่คุณเพิ่งโคลน:
./gen-timeseries-data.shหมายเหตุ—เพียงแค่ใช้คำสั่ง mosquitto_pub CLI เพื่อส่งข้อมูล
ข้อมูลถูกส่งไปยังหัวข้อ MQTT ของสถิติอุปกรณ์ (นี่คือ ไม่ใช่ หัวข้อคาฟคา) คุณสามารถตรวจสอบได้อีกครั้งโดยใช้สมาชิก CLI:
mosquitto_sub -h localhost -t device-statsตรวจสอบหัวข้อ Kafka ในพอร์ทัล Confused Cloud คุณควรตรวจสอบบันทึกสำหรับแอปตัวประมวลผลข้อมูลอุปกรณ์ใน Azure Spring Cloud:
az spring-cloud app logs -f -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group>เพลิดเพลินไปกับแดชบอร์ด Grafana!
เรียกดู Grafana UI ที่ localhost:3000
ปลั๊กอินแหล่งข้อมูล Redis สำหรับ Grafana ทำงานร่วมกับฐานข้อมูล Redis ใดๆ รวมถึง Azure Cache สำหรับ Redis ทำตามคำแนะนำในบล็อกโพสต์นี้เพื่อกำหนดค่าแหล่งข้อมูล
นำเข้าแดชบอร์ดในโฟลเดอร์ grafana_dashboards ใน GitHub repo ที่คุณโคลนไว้ (โปรดดูเอกสาร Grafana หากคุณต้องการความช่วยเหลือเกี่ยวกับวิธีการนำเข้าแดชบอร์ด)
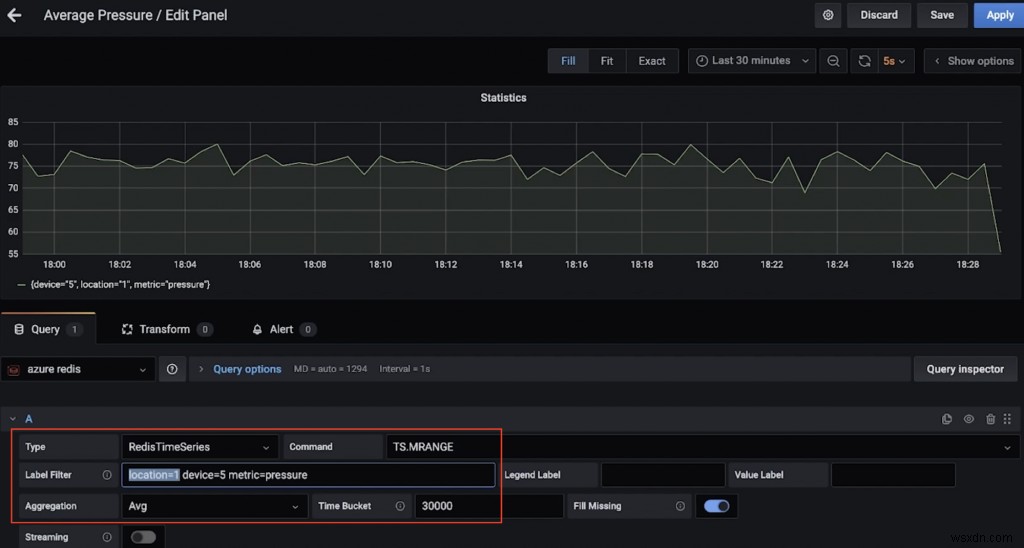
ตัวอย่างเช่น นี่คือแดชบอร์ดที่แสดงแรงกดเฉลี่ย (มากกว่า 30 วินาที) สำหรับอุปกรณ์ 5 ในตำแหน่งที่ 1 (ใช้ TS.MRANGE)
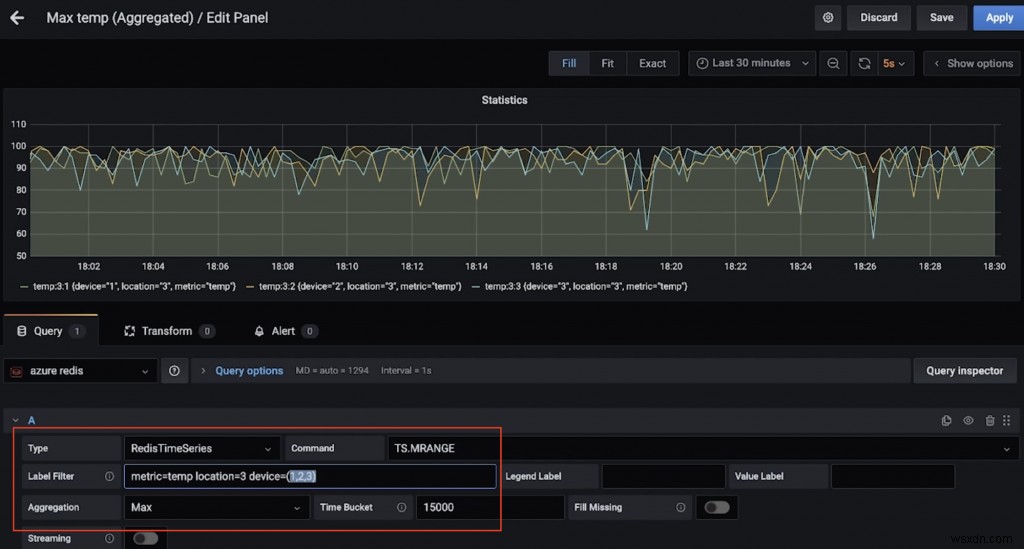
นี่คือแดชบอร์ดอื่นที่แสดงอุณหภูมิสูงสุด (มากกว่า 15 วินาที) สำหรับอุปกรณ์หลายเครื่องในตำแหน่งที่ 3 (ขอบคุณ TS.MRANGE อีกครั้ง)
คุณต้องการเรียกใช้คำสั่ง RedisTimeSeries หรือไม่
เร่งความเร็ว redis-cli และเชื่อมต่อกับอินสแตนซ์ Azure Cache สำหรับ Redis:
redis-cli -h <azure redis hostname e.g. myredis.southeastasia.redisenterprise.cache.azure.net> -p 10000 -a <azure redis access key> --tlsเริ่มต้นด้วยข้อความค้นหาง่ายๆ:
# pressure in device 5 for location 1
TS.GET pressure:1:5
# temperature in device 5 for location 4
TS.GET temp:4:5กรองตามสถานที่และรับอุณหภูมิและความดันสำหรับ ทั้งหมด อุปกรณ์:
TS.MGET WITHLABELS FILTER location=3ดึงอุณหภูมิและความดันสำหรับอุปกรณ์ทั้งหมดในหนึ่งตำแหน่งขึ้นไปภายในช่วงเวลาที่กำหนด:
TS.MRANGE - + WITHLABELS FILTER location=3
TS.MRANGE - + WITHLABELS FILTER location=(3,5)– + หมายถึงทุกอย่างตั้งแต่เริ่มต้นจนถึงการประทับเวลาล่าสุด แต่คุณสามารถเจาะจงมากกว่านี้ได้
MRANGE is what we needed! We can also filter by a specific device in a location and further drill down by either temperature or pressure:
TS.MRANGE - + WITHLABELS FILTER location=3 device=2
TS.MRANGE - + WITHLABELS FILTER location=3 metric=temp
TS.MRANGE - + WITHLABELS FILTER location=3 device=2 metric=tempทั้งหมดนี้สามารถนำมารวมกับการรวมได้
# all the temp data points are not useful. how about an average (or max) instead of every temp data points?
TS.MRANGE - + WITHLABELS AGGREGATION avg 10000 FILTER location=3 metric=temp
TS.MRANGE - + WITHLABELS AGGREGATION max 10000 FILTER location=3 metric=tempคุณยังสร้างกฎเพื่อรวบรวมและจัดเก็บไว้ในอนุกรมเวลาอื่นได้อีกด้วย
เมื่อเสร็จแล้ว อย่าลืมลบทรัพยากรเพื่อหลีกเลี่ยงค่าใช้จ่ายที่ไม่ต้องการ
ลบทรัพยากร
- ทำตามขั้นตอนในเอกสารประกอบเพื่อลบคลัสเตอร์ Confluence Cloud ทั้งหมดที่คุณต้องมีคือลบองค์กร Confluent
- ในทำนองเดียวกัน คุณควรลบอินสแตนซ์ Azure Cache สำหรับ Redis ด้วย
บนเครื่องท้องถิ่นของคุณ:
- หยุดคลัสเตอร์ Kafka Connect
- หยุดตัวแทนยุง (เช่น บริการชง หยุดยุง)
- หยุดบริการ Grafana (เช่น บริการชง หยุด Grafana)
เราสำรวจไปป์ไลน์ข้อมูลเพื่อนำเข้า ประมวลผล และสืบค้นข้อมูลอนุกรมเวลาโดยใช้ Redis และ Kafka เมื่อคุณนึกถึงขั้นตอนต่อไปและก้าวไปสู่โซลูชันเกรดการผลิต คุณควรพิจารณาอีกสองสามสิ่ง
ข้อควรพิจารณาเพิ่มเติม
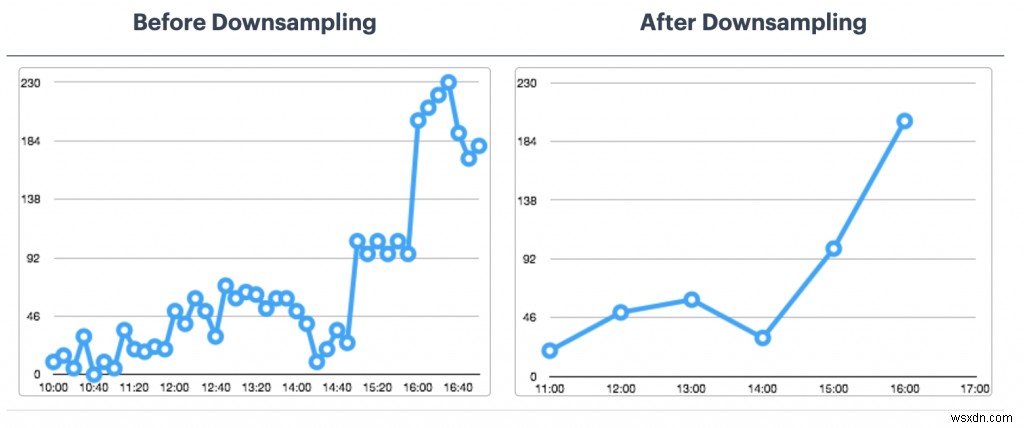
การเพิ่มประสิทธิภาพ RedisTimeSeries
- นโยบายการเก็บรักษา:คิดเกี่ยวกับเรื่องนี้เนื่องจากจุดข้อมูลอนุกรมเวลาของคุณไม่ ได้รับการตัดแต่งหรือลบโดยปริยาย
- กฎการสุ่มตัวอย่างและการรวมกลุ่ม:คุณไม่ต้องการเก็บข้อมูลตลอดไปใช่ไหม ตรวจสอบให้แน่ใจว่าได้กำหนดค่ากฎที่เหมาะสมเพื่อดูแลสิ่งนี้ (เช่น TS.CREATERULE temp:1:2 temp:avg:30 AGGREGATION avg 30000)
- นโยบายข้อมูลซ้ำ:คุณต้องการจัดการตัวอย่างที่ซ้ำกันอย่างไร ตรวจสอบให้แน่ใจว่านโยบายเริ่มต้น (BLOCK) เป็นสิ่งที่คุณต้องการอย่างแท้จริง ถ้าไม่ ให้พิจารณาทางเลือกอื่น
นี่ไม่ใช่รายการที่ละเอียดถี่ถ้วน สำหรับตัวเลือกการกำหนดค่าอื่นๆ โปรดดูเอกสาร RedisTimeSeries
การเก็บรักษาข้อมูลในระยะยาวเป็นอย่างไร
ข้อมูลมีค่า รวมถึงอนุกรมเวลาด้วย! คุณอาจต้องการประมวลผลเพิ่มเติม (เช่น เรียกใช้แมชชีนเลิร์นนิงเพื่อดึงข้อมูลเชิงลึก การบำรุงรักษาเชิงคาดการณ์ ฯลฯ) เพื่อให้เป็นไปได้ คุณจะต้องเก็บข้อมูลนี้ไว้เป็นระยะเวลานานขึ้น และเพื่อให้มีความคุ้มค่าและมีประสิทธิภาพ คุณจะต้องใช้บริการพื้นที่จัดเก็บอ็อบเจ็กต์ที่ปรับขนาดได้ เช่น Azure Data Lake Storage Gen2 (ADLS Gen2) .
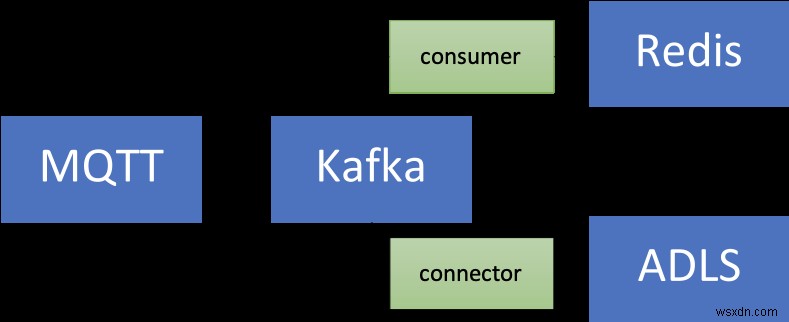
มีตัวเชื่อมต่อสำหรับสิ่งนั้น! คุณสามารถปรับปรุงไปป์ไลน์ข้อมูลที่มีอยู่โดยใช้ Azure Data Lake Storage Gen2 Sink Connector ที่มีการจัดการเต็มรูปแบบสำหรับ Confluence Cloud เพื่อประมวลผลและจัดเก็บข้อมูลใน ADLS จากนั้นเรียกใช้การเรียนรู้ของเครื่องโดยใช้ Azure Synapse Analytics หรือ Azure Databricks
ความสามารถในการปรับขนาด
ปริมาณข้อมูลอนุกรมเวลาของคุณสามารถเลื่อนขึ้นได้ทางเดียวเท่านั้น! จำเป็นอย่างยิ่งที่โซลูชันของคุณจะปรับขนาดได้:
- โครงสร้างพื้นฐานหลัก:บริการที่มีการจัดการช่วยให้ทีมมุ่งเน้นไปที่โซลูชันมากกว่าการตั้งค่าและบำรุงรักษาโครงสร้างพื้นฐาน โดยเฉพาะอย่างยิ่งเมื่อพูดถึงระบบแบบกระจายที่ซับซ้อน เช่น ฐานข้อมูลและแพลตฟอร์มการสตรีม เช่น Redis และ Kafka
- Kafka Connect:เท่าที่เกี่ยวข้องกับไปป์ไลน์ข้อมูล คุณอยู่ในมือที่ดีเนื่องจากแพลตฟอร์ม Kafka Connect นั้นไร้สัญชาติโดยธรรมชาติและสามารถปรับขนาดในแนวนอนได้ คุณมีตัวเลือกมากมายในแง่ของการออกแบบและกำหนดขนาดคลัสเตอร์ผู้ปฏิบัติงาน Kafka Connect ของคุณ
- แอปพลิเคชันที่กำหนดเอง:เช่นเดียวกับในโซลูชันนี้ เราได้สร้างแอปพลิเคชันที่กำหนดเองเพื่อประมวลผลข้อมูลในหัวข้อ Kafka โชคดีที่ลักษณะการปรับขนาดที่เหมือนกันก็มีผลเช่นเดียวกัน ในแง่ของขนาดแนวนอน จะถูกจำกัดโดยจำนวนของพาร์ทิชันหัวข้อ Kafka ที่คุณมี
บูรณาการ :ไม่ใช่แค่กราฟาน่า! RedisTimeSeries ยังทำงานร่วมกับ Prometheus และ Telegraf อย่างไรก็ตาม ไม่มีตัวเชื่อมต่อ Kafka ในขณะที่เขียนบล็อกนี้ นี่จะเป็นส่วนเสริมที่ยอดเยี่ยม!
บทสรุป

แน่นอน คุณสามารถใช้ Redis กับ (เกือบ) ได้ทุกอย่าง รวมถึงปริมาณงานอนุกรมเวลาด้วย! อย่าลืมนึกถึงสถาปัตยกรรมแบบ end-to-end สำหรับไปป์ไลน์ข้อมูลและการผสานรวมจากแหล่งข้อมูลอนุกรมเวลา ไปจนถึง Redis และอื่นๆ
