
ในบทความนี้ เราจะมาเรียนรู้เกี่ยวกับ Learning Model Building ใน Scikit-learn:A Python Machine Learning Library
เป็นห้องสมุดการเรียนรู้ของเครื่องฟรี รองรับอัลกอริธึมที่หลากหลาย เช่น Random Forest, Vector Machine &k-Nearest Neighbors ด้วยการนำไปปฏิบัติโดยตรงด้วย numpy และ scipy
การนำเข้าชุดข้อมูล
import pandas Url = < specify your URL here> data=pandas.rad_csv(url)
การสำรวจและทำความสะอาดข้อมูล
เราสามารถใช้ head method เพื่อระบุ/กรองข้อมูลได้ตามความต้องการ
data.head() data.head(n=4) # restricting the record to be 4
เรายังสามารถใช้บันทึกสองสามชุดสุดท้ายของชุดข้อมูลได้
data.tail() data.tail(n=4) # restricting the record to be 4
มาถึงขั้นตอนของการแสดงข้อมูลเป็นภาพแล้ว
สำหรับสิ่งนี้ เราใช้โมดูล Seaborn และ matplotlib เพื่อแสดงภาพข้อมูลของเรา
import seaborn as s
import matplotlib.pyplot as plt
sns.set(style="whitegrid", color_codes=True)
# create a countplot
sns.countplot('Route To Market',data=sales_data,hue = 'Opportunity Result') กำลังประมวลผลข้อมูลล่วงหน้า
from sklearn import preprocessing le = preprocessing.LabelEncoder() #convert the columns into numeric values encoded_value = le.fit_transform(list of column names) print(encoded_value)
ในที่สุด เราก็มาถึงขั้นตอนของการสร้างแบบจำลองโดยการฝึกชุดข้อมูล
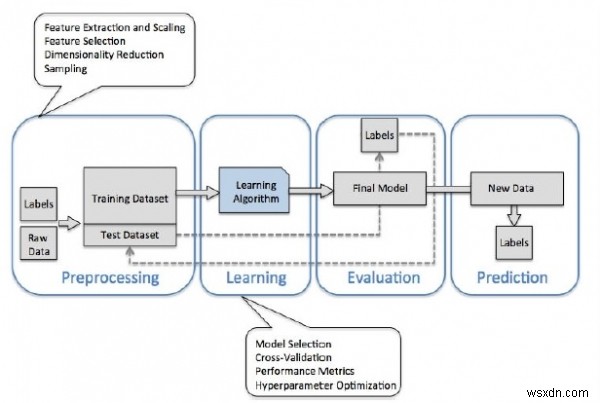
บทสรุป
ในบทความนี้ เราได้เรียนรู้เกี่ยวกับการสร้างแบบจำลองใน scikit-learn ซึ่งเป็นไลบรารี่ที่มีอยู่ใน Python
