ปัญหา:
สิ่งที่ท้าทายที่สุดประการหนึ่งสำหรับนักวิทยาศาสตร์ด้านข้อมูลคือการรวบรวมข้อมูล แม้ว่าข้อเท็จจริงคือ มีข้อมูลมากมายในเว็บ เพียงแต่ดึงข้อมูลผ่านระบบอัตโนมัติ
แนะนำตัว..
ฉันต้องการดึงข้อมูลการทำงานพื้นฐานที่ฝังอยู่ในตาราง HTML จาก https://www.tutorialspoint.com/python/python_basic_operators.htm
อืม ข้อมูลกระจัดกระจายอยู่ในตาราง HTML หลายตาราง ถ้าเห็นได้ชัดว่ามีตาราง HTML เพียงตารางเดียว ฉันสามารถใช้ Copy &Paste เป็นไฟล์ .csv ได้
อย่างไรก็ตาม หากมีมากกว่า 5 ตารางในหน้าเดียว แสดงว่าเป็นความเจ็บปวด ใช่ไหม ?
ทำอย่างไร..
1. ฉันจะแสดงวิธีสร้างไฟล์ csv อย่างง่ายดายอย่างรวดเร็วหากคุณต้องการสร้างไฟล์ csv
import csv
# Open File in Write mode , if not found it will create one
File = open('test.csv', 'w+')
Data = csv.writer(File)
# My Header
Data.writerow(('Column1', 'Column2', 'Column3'))
# Write data
for i in range(20):
Data.writerow((i, i+1, i+2))
# close my file
File.close() ผลลัพธ์
โค้ดด้านบนเมื่อเรียกใช้งานจะสร้างไฟล์ test.csv โดยมีอยู่ในไดเร็กทอรีเดียวกันกับโค้ดนี้
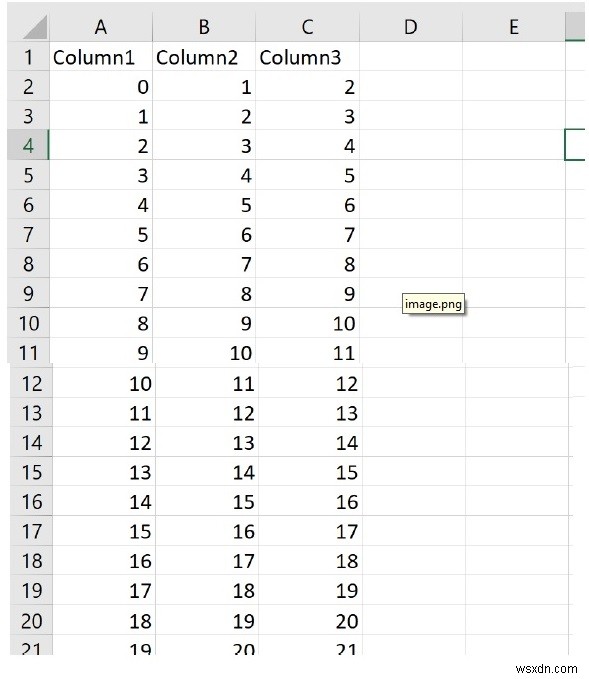
2. ให้เราเรียกตาราง HTML จาก https://www.tutorialspoint.com/python/python_dictionary.htm และเขียนเป็นไฟล์ CSV
ขั้นตอนแรกคือการนำเข้า
import csv from urllib.request import urlopen from bs4 import BeautifulSoup url = 'https://www.tutorialspoint.com/python/python_dictionary.htm'
-
เปิดไฟล์ HTML และเก็บไว้ในวัตถุ html โดยใช้ urlopen
ผลลัพธ์
html = urlopen(url) soup = BeautifulSoup(html, 'html.parser')
-
ค้นหาตารางภายในตาราง html และให้เรานำข้อมูลตารางมา เพื่อจุดประสงค์ในการสาธิต ฉันจะดึงเฉพาะตารางแรกเท่านั้น [0]
ผลลัพธ์
table = soup.find_all('table')[0]
rows = table.find_all('tr') ผลลัพธ์
print(rows)
ผลลัพธ์
[<tr> <th style='text-align:center;width:5%'>Sr.No.</th> <th style='text-align:center;width:95%'>Function with Description</th> </tr>, <tr> <td class='ts'>1</td> <td><a href='/python/dictionary_cmp.htm'>cmp(dict1, dict2)</a> <p>Compares elements of both dict.</p></td> </tr>, <tr> <td class='ts'>2</td> <td><a href='/python/dictionary_len.htm'>len(dict)</a> <p>Gives the total length of the dictionary. This would be equal to the number of items in the dictionary.</p></td> </tr>, <tr> <td class='ts'>3</td> <td><a href='/python/dictionary_str.htm'>str(dict)</a> <p>Produces a printable string representation of a dictionary</p></td> </tr>, <tr> <td class='ts'>4</td> <td><a href='/python/dictionary_type.htm'>type(variable)</a> <p>Returns the type of the passed variable. If passed variable is dictionary, then it would return a dictionary type.</p></td> </tr>]
5.ตอนนี้เราจะเขียนข้อมูลลงในไฟล์ csv
ตัวอย่าง
File = open('my_html_data_to_csv.csv', 'wt+')
Data = csv.writer(File)
try:
for row in rows:
FilteredRow = []
for cell in row.find_all(['td', 'th']):
FilteredRow.append(cell.get_text())
Data.writerow(FilteredRow)
finally:
File.close() 6. ผลลัพธ์จะถูกบันทึกลงในไฟล์ my_html_data_to_csv.csv
ตัวอย่าง
เราจะนำทุกอย่างที่อธิบายข้างต้นมารวมกัน
ตัวอย่าง
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
# set the url..
url = 'https://www.tutorialspoint.com/python/python_basic_syntax.htm'
# Open the url and parse the html
html = urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
# extract the first table
table = soup.find_all('table')[0]
rows = table.find_all('tr')
# write the content to the file
File = open('my_html_data_to_csv.csv', 'wt+')
Data = csv.writer(File)
try:
for row in rows:
FilteredRow = []
for cell in row.find_all(['td', 'th']):
FilteredRow.append(cell.get_text())
Data.writerow(FilteredRow)
finally:
File.close() ตารางในหน้า html