
คุณจะทำอย่างไรถ้าคุณมีข้อความจำนวนมากและต้องการแยกความหมายออกจากข้อความนั้น
การเริ่มต้นที่ดีคือแบ่งข้อความออกเป็น n-grams .
นี่คือคำอธิบาย :
ในสาขาภาษาศาสตร์เชิงคำนวณและความน่าจะเป็น n-gram คือลำดับที่ต่อเนื่องกันของ n รายการจากลำดับข้อความที่กำหนด – วิกิพีเดีย
ตัวอย่างเช่น :
หากเราใช้คำว่า “สวัสดี สบายดีไหม” จากนั้นยูนิแกรม (ngrams ขององค์ประกอบหนึ่ง) จะเป็น:"Hello", "there", "how", "are", "you" และ bigrams (ngrams ของสององค์ประกอบ):["Hello", "there"], ["there", "how"], ["how", "are"], ["are", "you"] .
หากคุณเรียนรู้ได้ดีขึ้นด้วยรูปภาพ นี่คือรูปภาพ:
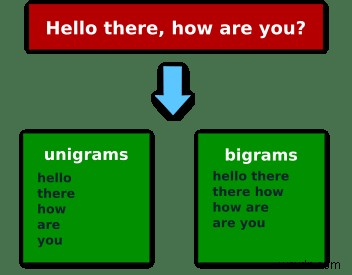
ตอนนี้เรามาดูกันว่าคุณจะใช้สิ่งนี้ใน Ruby ได้อย่างไร!
กำลังดาวน์โหลดข้อมูลตัวอย่าง
ก่อนที่เราจะทำมือสกปรก เราต้องการข้อมูลตัวอย่างก่อน
หากคุณไม่มีงานใดๆ คุณสามารถดาวน์โหลด Wikipedia หรือบทความในบล็อกได้ ในกรณีนี้ ฉันตัดสินใจดาวน์โหลดบันทึก IRC บางรายการจากช่องของ #ruby freenode
สามารถดูบันทึกได้ที่นี่ :
irclog.whitequark.org/ruby
หมายเหตุเกี่ยวกับรูปแบบข้อมูล :
หากไม่มีเวอร์ชันข้อความธรรมดาของทรัพยากรที่คุณต้องการวิเคราะห์ คุณสามารถใช้ Nokogiri เพื่อแยกวิเคราะห์หน้าและดึงข้อมูลได้
บันทึก irc มีอยู่ในข้อความธรรมดาโดยต่อท้าย .txt ที่ส่วนท้ายของ URL ดังนั้นเราจะใช้ประโยชน์จากสิ่งนั้น
ชั้นเรียนนี้จะดาวน์โหลดและบันทึกข้อมูลให้เรา:
require 'restclient'
class LogParser
LOG_DIR = 'irc_logs'
def initialize(date)
@date = date
@log_name = "#{LOG_DIR}/irc-log-#{@date}.txt"
end
def download_page(url)
return log_contents if File.exist? @log_name
RestClient.get(url).body
end
def save_page(page)
File.open(@log_name, "w+") { |f| f.puts page }
end
def log_contents
File.readlines(@log_name).join
end
def get_messages
page = download_page("https://irclog.whitequark.org/ruby/#{@date}.txt")
save_page(page)
page
end
end
log = LogParser.new("2015-04-15")
msg = log.get_messages
นี่เป็นชั้นเรียนที่ค่อนข้างตรงไปตรงมา
เราใช้ RestClient เป็นไคลเอนต์ HTTP ของเรา จากนั้นเราบันทึกผลลัพธ์ในไฟล์ ดังนั้นเราจึงไม่ต้องร้องขอหลายครั้งในขณะที่เราทำการแก้ไขโปรแกรมของเรา
วิเคราะห์ข้อมูล
เมื่อเรามีข้อมูลแล้ว เราก็สามารถวิเคราะห์ได้
นี่คือคลาส Ngram ง่ายๆ
ในคลาสนี้เราใช้เมธอด Array#each_cons ซึ่งสร้าง ngrams
เนื่องจากวิธีนี้ส่งคืน Enumerator เราต้องเรียก to_a เพื่อรับ Array .
class Ngram
def initialize(input)
@input = input
end
def ngrams(n)
@input.split.each_cons(n).to_a
end
end
จากนั้นเราก็รวมทุกอย่างเข้าด้วยกันโดยใช้ลูป Hash#merge! &Enumerable#sort_by .
ถูกใจสิ่งนี้ :
# Filter words that appear less times than this
MIN_REPETITIONS = 20
total = {}
# Get the logs for the first 15 days of the month and return the bigrams
(1..15).each do |n|
day = '%02d' % [n]
total.merge!(get_trigrams_for_date "2015-04-#{day}") { |k, old, new| old + new }
end
# Sort in descending order
total = total.sort_by { |k, v| -v }.reject { |k, v| v < MIN_REPETITIONS }
total.each { |k, v| puts "#{v} => #{k}" }
หมายเหตุ:
get_trigrams_for_dateเมธอดไม่ได้อยู่ที่นี่เพื่อความกระชับ แต่คุณสามารถหาได้ใน github
นี่คือสิ่งที่ผลลัพธ์ออกมา :
112 => i want to 83 => link for more 82 => is there a 71 => you want to 66 => i don't know 66 => i have a 65 => i need to
อย่างที่คุณเห็น อยากทำสิ่งต่างๆ เป็นที่นิยมอย่างมากใน #ruby 🙂
บทสรุป
ตอนนี้ถึงตาคุณแล้ว!
เปิดโปรแกรมแก้ไขของคุณและเริ่มเล่นกับการวิเคราะห์ n-gram อีกวิธีหนึ่งในการดูการทำงานของ n-grams คือ Google Ngram Viewer
การประมวลผลภาษาธรรมชาติ (NLP) อาจเป็นหัวข้อที่น่าสนใจ Wikipedia มีภาพรวมที่ดีของหัวข้อ
คุณสามารถค้นหาโค้ดที่สมบูรณ์สำหรับโพสต์นี้ได้ที่นี่:https://github.com/matugm/ngram-analysis/blob/master/irc_histogram.rb
