
โพสต์นี้เกี่ยวกับสิ่งที่อยู่ในความคิดของฉัน มีสองสิ่งที่น่าตื่นเต้นที่สุดในโลก:โครงสร้างข้อมูลความน่าจะเป็นและโมดูล Redis หากคุณเคยได้ยินเกี่ยวกับเรื่องใดเรื่องหนึ่งมาก่อน คุณก็สามารถเชื่อมโยงกับความกระตือรือร้นของฉันได้ แต่ในกรณีที่คุณต้องการติดตามเรื่องราวที่เจ๋งที่สุดในโลก ให้อ่านต่อไป
ฉันจะเริ่มต้นด้วยข้อความนี้:การประมวลผลข้อมูลที่มีเวลาแฝงต่ำในระดับสูงเป็นสิ่งที่ท้าทาย ปริมาณและความเร็วของข้อมูลที่เกี่ยวข้องสามารถทำให้การวิเคราะห์แบบเรียลไทม์มีความต้องการสูง เนื่องจากประสิทธิภาพและความเก่งกาจสูง Redis มักใช้เพื่อแก้ปัญหาดังกล่าว ความสามารถในการจัดเก็บ จัดการ และให้บริการข้อมูลหลายรูปแบบในช่วงเวลาแฝงที่ต่ำกว่ามิลลิวินาที ทำให้เป็นที่เก็บข้อมูลในอุดมคติในหลายกรณีที่ต้องการการคำนวณแบบออนไลน์
แต่ทุกอย่างสัมพันธ์กัน และมีมาตราส่วนมากจนทำให้การวิเคราะห์แบบเรียลไทม์ที่แม่นยำเป็นไปไม่ได้ในทางปฏิบัติ ปัญหาที่ซับซ้อนจะยิ่งยากขึ้นเมื่อปัญหาใหญ่ขึ้น แต่เรามักจะลืมไปว่าปัญหาง่ายๆ นั้นใช้กฎเดียวกัน แม้แต่สิ่งพื้นฐานอย่างการบวกตัวเลขก็สามารถกลายเป็นงานที่ยิ่งใหญ่ได้เมื่อข้อมูลมีขนาดใหญ่เกินไป เร็วเกินไป หรือเมื่อเราไม่มีทรัพยากรเพียงพอที่จะประมวลผล และในขณะที่ทรัพยากรมีจำกัดและมีราคาแพง ข้อมูลก็เติบโตอย่างต่อเนื่องเหมือนธุรกิจของใครๆ
การนับนาที Sketch คืออะไร
Count-min sketch (หรือที่เรียกว่า CM sketch) เป็นโครงสร้างข้อมูลความน่าจะเป็นที่มีประโยชน์อย่างยิ่งเมื่อคุณเข้าใจวิธีการทำงานและที่สำคัญกว่านั้นคือวิธีใช้งาน
โชคดีที่ลักษณะที่เรียบง่ายของ CM Sketch ทำให้มือใหม่เข้าใจได้ง่าย (ปรากฏว่าเพื่อนของฉันไม่สามารถติดตามบล็อก Top-K นี้ได้)
CM Sketch เป็นโมดูล Redis มาหลายปีแล้ว และเพิ่งถูกเขียนใหม่โดยเป็นส่วนหนึ่งของโมดูล RedisBloom v2.0 แต่ก่อนที่เราจะลงลึกใน CM Sketch สิ่งสำคัญคือต้องเข้าใจว่าทำไมคุณถึงใช้ any โครงสร้างข้อมูลความน่าจะเป็น ในรูปสามเหลี่ยมของความเร็ว พื้นที่ และความแม่นยำ โครงสร้างข้อมูลความน่าจะเป็นยอมสละความแม่นยำบางส่วนเพื่อให้ได้พื้นที่ ซึ่งมีโอกาส พื้นที่มาก ! ผลกระทบต่อความเร็วแตกต่างกันไปตามอัลกอริทึมและขนาดชุด
- ความแม่นยำ :ตามคำจำกัดความ การเก็บข้อมูลของคุณเพียงบางส่วนและอนุญาตให้มีการชนกันในที่จัดเก็บจะลดความถูกต้องลง แต่คุณสามารถกำหนดอัตราข้อผิดพลาดสูงสุดตามกรณีการใช้งานของคุณได้
- พื้นที่หน่วยความจำ :ในโลกของข้อมูลขนาดใหญ่ที่มีการบันทึกเหตุการณ์หลายพันล้านรายการ การจัดเก็บข้อมูลเพียงบางส่วนเท่านั้นสามารถลดความต้องการและค่าใช้จ่ายของพื้นที่จัดเก็บได้อย่างมาก
- ความเร็ว :โครงสร้างข้อมูลแบบดั้งเดิมบางอย่างทำงานค่อนข้างไม่มีประสิทธิภาพ ทำให้เวลาตอบสนองช้าลง (ตัวอย่างเช่น Sorted Set จะรักษาลำดับขององค์ประกอบทั้งหมดในนั้น แต่คุณอาจสนใจเพียงแค่องค์ประกอบด้านบน เนื่องจากอัลกอริธึมความน่าจะเป็นจะรักษาเพียงรายการบางส่วนเท่านั้น พวกเขาจึงมีประสิทธิภาพมากกว่าและมักจะสามารถตอบคำถามได้เร็วกว่ามาก
โครงสร้างข้อมูลความน่าจะเป็นที่เหมาะสมช่วยให้คุณเก็บข้อมูลบางส่วนในชุดข้อมูลของคุณเพื่อแลกกับความแม่นยำที่ลดลง แน่นอนว่าในหลายกรณี (เช่น บัญชีธนาคาร) ความแม่นยำที่ลดลงนั้นเป็นสิ่งที่ยอมรับไม่ได้ แต่สำหรับการแนะนำภาพยนตร์หรือการแสดงโฆษณาแก่ผู้ใช้เว็บไซต์ ข้อผิดพลาดที่ค่อนข้างหายากนั้นต่ำและประหยัดพื้นที่ได้มาก
โดยพื้นฐานแล้ว CM sketch ทำงานโดยรวมการนับรายการทั้งหมดในชุดข้อมูลของคุณเป็นอาร์เรย์ตัวนับหลายตัว เมื่อมีการสืบค้นข้อมูลจะส่งกลับจำนวนขั้นต่ำของรายการของอาร์เรย์ทั้งหมดซึ่งสัญญาว่าจะลดอัตราเงินเฟ้อที่เกิดจากการชนกัน รายการที่มีอัตราการปรากฏหรือคะแนนต่ำ ("การไหลของเมาส์") มีจำนวนต่ำกว่า อัตราข้อผิดพลาด ดังนั้นคุณจึงสูญเสียข้อมูลเกี่ยวกับจำนวนจริงของพวกมันและจะถือว่าเป็นสัญญาณรบกวน สำหรับรายการที่มีอัตราการปรากฏตัวหรือคะแนนสูง ("กระแสช้าง") เพียงใช้จำนวนที่ได้รับ เมื่อพิจารณาว่าขนาดร่าง CM คงที่และสามารถใช้ได้กับสินค้าจำนวนไม่จำกัด คุณจึงเห็นศักยภาพในการประหยัดพื้นที่จัดเก็บได้มาก
สำหรับพื้นหลัง สเก็ตช์คือคลาสของโครงสร้างข้อมูลและอัลกอริธึมที่มาพร้อมกัน พวกเขาจับธรรมชาติของข้อมูลของคุณเพื่อตอบคำถามเกี่ยวกับมันในขณะที่ใช้ช่องว่างคงที่หรือ sublinear ภาพร่าง CM อธิบายโดย Graham Cormode และ S. Muthu Muthukrishnan ในบทความปี 2005 ชื่อ “ ข้อมูลสรุปสตรีมข้อมูลที่ปรับปรุง:Count-Min Sketch และแอปพลิเคชัน”
Count-min Sketch:อะไรและอย่างไร
CM sketch ใช้อาร์เรย์ของตัวนับหลายตัวเพื่อรองรับกรณีการใช้งานหลัก เรียกจำนวนอาร์เรย์ว่า "ความลึก" และจำนวนตัวนับในแต่ละอาร์เรย์ "ความกว้าง"
เมื่อใดก็ตามที่เราได้รับรายการ เราใช้ฟังก์ชันแฮช (ซึ่งเปลี่ยนองค์ประกอบ—คำ ประโยค ตัวเลข หรือไบนารี—เป็นตัวเลขที่สามารถใช้เป็นตำแหน่งในชุด/อาร์เรย์ หรือเป็นลายนิ้วมือ) เพื่อคำนวณ ตำแหน่งของรายการและเพิ่มตัวนับสำหรับแต่ละอาร์เรย์ ตัวนับที่เกี่ยวข้องแต่ละตัวมีค่าเท่ากับหรือสูงกว่ามูลค่าที่แท้จริงของรายการ เมื่อเราทำการสอบถาม เราจะดำเนินการผ่านอาร์เรย์ทั้งหมดที่มีฟังก์ชันแฮชเดียวกัน และดึงข้อมูลตัวนับที่เกี่ยวข้องกับรายการของเรา จากนั้นเราจะคืนค่าขั้นต่ำที่เราพบเนื่องจากเรารู้ว่าค่าของเราสูงเกินจริง (หรือเท่ากัน)
แม้ว่าเราจะทราบดีว่าสิ่งของจำนวนมากมีส่วนทำให้เกิดเคาน์เตอร์ส่วนใหญ่ เนื่องจากการชนกันตามธรรมชาติ (เมื่อสิ่งของต่างกันได้รับตำแหน่งเดียวกัน) เรายอมรับ "เสียง" ตราบเท่าที่ยังอยู่ในอัตราความผิดพลาดที่ต้องการ
ตัวอย่างร่างการนับนาที
คณิตศาสตร์กำหนดว่าด้วยความลึก 10 และความกว้าง 2,000 ความน่าจะเป็นที่จะไม่มีข้อผิดพลาดคือ 99.9% และอัตราความผิดพลาดคือ 0.1% (นี่คือเปอร์เซ็นต์ของการเพิ่มทั้งหมด ไม่ใช่ของรายการที่ไม่ซ้ำ)
ในจำนวนจริง หมายความว่า หากคุณเพิ่มไอเท็มที่ไม่ซ้ำกัน 1 ล้านชิ้น โดยเฉลี่ย แต่ละรายการจะได้รับมูลค่า 500 (1M/2K) แม้ว่าจะดูไม่สมส่วน แต่ก็อยู่ในอัตราความผิดพลาดของเราที่ 0.1% ซึ่งเท่ากับ 1,000 ใน 1 ล้านรายการ
ในทำนองเดียวกัน หากช้าง 10 ตัวปรากฏตัวละ 10,000 ครั้ง ค่าของช้างทุกชุดจะเท่ากับ 10,000 หรือมากกว่า เมื่อใดที่เรานับมันในอนาคต เราจะเห็นช้างอยู่ข้างหน้าเรา สำหรับตัวเลขอื่นๆ ทั้งหมด (เช่น หนูทุกตัวที่มีจำนวนจริงคือ 1) ไม่น่าจะชนกับช้างในทุกชุด (เนื่องจาก CM sketch พิจารณาเฉพาะจำนวนขั้นต่ำ) เนื่องจากความน่าจะเป็นของเหตุการณ์นี้จะน้อยมากและลดลงอีกหากคุณ เพิ่มความลึกเมื่อคุณเริ่มต้นร่าง CM
Count-min Sketch เหมาะสำหรับอะไร?
ตอนนี้เราเข้าใจพฤติกรรมของภาพร่าง CM แล้ว เราจะทำอะไรกับสัตว์ตัวน้อยตัวนี้ได้บ้าง ต่อไปนี้คือกรณีการใช้งานทั่วไป:
- ค้นหาตัวเลขสองตัวและเปรียบเทียบจำนวน
- กำหนดเปอร์เซ็นต์ของรายการที่เข้ามา สมมติว่า 1% เมื่อใดก็ตามที่จำนวนขั้นต่ำของไอเท็มสูงกว่า 1% ของจำนวนทั้งหมด เราจะคืนค่าเป็น จริง สามารถใช้ระบุผู้เล่นอันดับต้นๆ ของเกมออนไลน์ได้ เป็นต้น
- เพิ่ม min-heap ให้กับ CM sketch และสร้างโครงสร้างข้อมูล Top-K เมื่อใดก็ตามที่เราเพิ่มรายการ เราจะตรวจสอบว่าจำนวนขั้นต่ำใหม่นั้นสูงกว่าค่าต่ำสุดในฮีปหรือไม่ และอัปเดตตามนั้น ไม่เหมือนกับโมดูล Top-K ใน RedisBloom ซึ่งค่อยๆ เสื่อมสลายไปตามกาลเวลา CM Sketch ไม่เคยลืม ดังนั้นพฤติกรรมของมันจึงแตกต่างจาก HeavyKeeper เล็กน้อย -based Top-K.
ใน RedisBloom API สำหรับร่าง CM นั้นง่ายและสะดวก:
- ในการเริ่มต้นโครงสร้างข้อมูลร่าง CM:INITBYDIM {key } {ความกว้าง } {ความลึก } หรือ CMS.INITBYPROB {คีย์ } {ข้อผิดพลาด } {ความน่าจะเป็น }
- ในการเพิ่มตัวนับของรายการ:CMS.INCRBY {key } {รายการ } {เพิ่มขึ้น }
- ในการรับจำนวนขั้นต่ำที่พบในตัวนับของรายการ:CMS.QUERY {key } {รายการ }
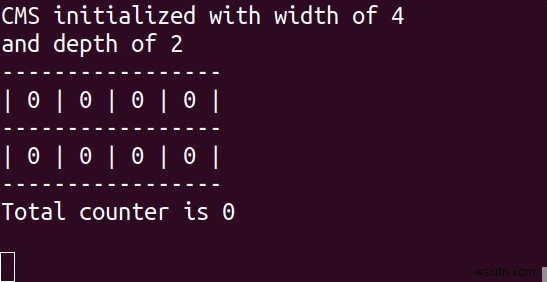
คำสั่งต่อไปนี้ถูกใช้เพื่อสร้างตัวอย่างภาพเคลื่อนไหวที่ด้านบนของโพสต์นี้:
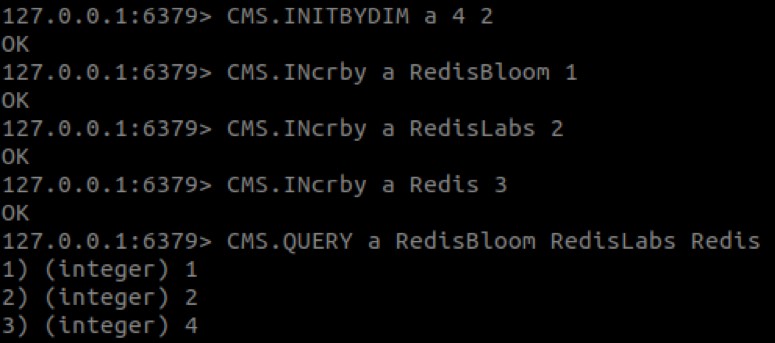
อย่างที่คุณเห็น ค่าของ 'Redis' คือ 4 แทนที่จะเป็น 3 ลักษณะการทำงานนี้คาดว่าเนื่องจากในร่าง CM จำนวนรายการมีแนวโน้มที่จะพองตัว
ธุรกิจคร่าวๆ
วิศวกรรมซอฟต์แวร์เป็นเรื่องเกี่ยวกับการแลกเปลี่ยน และแนวทางที่นิยมในการจัดการกับความท้าทายดังกล่าวด้วยวิธีที่ประหยัดต้นทุนคือการละทิ้งความถูกต้องเพื่อเพิ่มประสิทธิภาพ แนวทางนี้เป็นตัวอย่างโดยการนำ HyperLogLog ของ Redis ไปใช้ ซึ่งเป็นโครงสร้างข้อมูลที่ออกแบบมาเพื่อให้คำตอบสำหรับคำถามเกี่ยวกับการกำหนดจำนวนชุดข้อมูลอย่างมีประสิทธิภาพ HyperLogLog เป็นสมาชิกของกลุ่มโครงสร้างข้อมูลที่เรียกว่า "ภาพร่าง" ซึ่งเหมือนกับคู่หูทางศิลปะในโลกแห่งความเป็นจริง ถ่ายทอดข้อมูลผ่านการประมาณของวัตถุ
ในภาพรวมกว้างๆ สเก็ตช์คือโครงสร้างข้อมูล (และอัลกอริธึมที่มาพร้อมกัน) ที่จับลักษณะของข้อมูลของคุณ—คำตอบสำหรับคำถามของคุณเกี่ยวกับข้อมูล โดยไม่ต้องจัดเก็บข้อมูลจริงๆ กล่าวอย่างเป็นทางการว่าภาพสเก็ตช์มีประโยชน์เนื่องจากมีความซับซ้อนในการคำนวณเชิงซีมโทติกใต้เส้นใต้ จึงต้องใช้กำลังในการคำนวณและ/หรือพื้นที่จัดเก็บน้อยลง แต่ไม่มีอาหารกลางวันฟรีและประสิทธิภาพที่เพิ่มขึ้นถูกชดเชยด้วยความถูกต้องของคำตอบ อย่างไรก็ตาม ในหลายกรณี ข้อผิดพลาดเป็นที่ยอมรับได้ตราบเท่าที่สามารถเก็บไว้ใต้เกณฑ์ได้ สเก็ตช์ข้อมูลที่ดีคือแบบที่ยอมรับข้อผิดพลาดได้ง่าย และอันที่จริง สเก็ตช์จำนวนมากกำหนดพารามิเตอร์ของข้อผิดพลาด (หรือความน่าจะเป็นของข้อผิดพลาดดังกล่าว) เพื่อให้ผู้ใช้สามารถกำหนดได้
สเก็ตช์ที่ดีนั้นมีประสิทธิภาพและมีความเป็นไปได้ที่จะเกิดข้อผิดพลาด แต่สเก็ตช์ที่ยอดเยี่ยมคือสิ่งที่สามารถคำนวณได้แบบคู่ขนาน สเก็ตช์แบบขนานเป็นสิ่งที่สามารถจัดเตรียมได้อย่างอิสระในส่วนของข้อมูล และช่วยให้รวมส่วนต่างๆ เข้าด้วยกันเป็นการรวมที่มีความหมายและสม่ำเสมอ เนื่องจากภาพสเก็ตช์ที่ยอดเยี่ยมแต่ละชิ้นสามารถคำนวณได้จากสถานที่และ/หรือเวลาที่แตกต่างกัน การขนานกันทำให้สามารถใช้แนวทางการแบ่งแยกและพิชิตที่ตรงไปตรงมาเพื่อแก้ปัญหาการปรับขนาดได้
มีปัญหาบ่อย
HyperLogLog ดังกล่าวเป็นภาพร่างที่ยอดเยี่ยม แต่เหมาะสำหรับการตอบคำถามบางประเภทเท่านั้น เครื่องมือล้ำค่าอีกอย่างหนึ่งคือ Count Min Sketch (CMS) ตามที่อธิบายไว้ในบทความเรื่อง “An Improved Data Stream Summary:The Count-Min Sketch and its Applications” โดย G. Cormode และ S. Muthukrishnan การคุมกำเนิดที่ชาญฉลาดนี้สร้างขึ้นเพื่อให้คำตอบเกี่ยวกับความถี่ของตัวอย่าง ซึ่งเป็นองค์ประกอบพื้นฐานทั่วไปในกระบวนการวิเคราะห์ที่มีเปอร์เซ็นต์สูง
ด้วยเวลาและทรัพยากรที่เพียงพอ การคำนวณความถี่ของตัวอย่างจึงเป็นกระบวนการง่ายๆ เพียงนับการสังเกต (ครั้งที่เห็น) สำหรับแต่ละตัวอย่าง (สิ่งที่เห็น) แล้วหารด้วยจำนวนการสังเกตทั้งหมดเพื่อให้ได้ความถี่ของตัวอย่างนั้น อย่างไรก็ตาม ด้วยบริบทของการประมวลผลข้อมูลที่มีเวลาแฝงต่ำในระดับสูง จึงไม่มีเวลาหรือทรัพยากรเพียงพอ คำตอบจะต้องได้รับทันทีเมื่อมีการสตรีมข้อมูล โดยไม่คำนึงถึงขนาด และขนาดที่แท้จริงของพื้นที่สุ่มตัวอย่างทำให้ไม่สามารถเก็บตัวนับสำหรับแต่ละตัวอย่างได้
ดังนั้น แทนที่จะติดตามแต่ละตัวอย่างอย่างแม่นยำ เราสามารถลองประมาณความถี่ได้ วิธีหนึ่งในการดำเนินการก็คือสุ่มสุ่มตัวอย่างการสังเกตและหวังว่าตัวอย่างโดยทั่วไปจะสะท้อนถึงคุณสมบัติของทั้งหมด ปัญหาของแนวทางนี้คือการทำให้มั่นใจว่าการสุ่มที่แท้จริงเป็นงานที่ยาก ดังนั้นความสำเร็จของการสุ่มตัวอย่างอาจถูกจำกัดโดยกระบวนการคัดเลือกของเราและ/หรือคุณสมบัติของข้อมูลเอง นั่นคือที่ที่ CMS เข้ามาด้วยวิธีการที่แตกต่างกันอย่างสิ้นเชิง ซึ่งในตอนแรกอาจดูเหมือนตรงกันข้ามกับภาพร่างที่ยอดเยี่ยม:CMS ไม่เพียงแต่บันทึกการสังเกตแต่ละครั้งเท่านั้น แต่ยังบันทึกแต่ละรายการด้วยตัวนับหลายตัว!
แน่นอนว่ามีจุดหักมุม และมันก็ฉลาดพอๆ กับความเรียบง่าย เอกสารต้นฉบับ (และเวอร์ชันที่เบากว่าซึ่งเรียกว่า "การประมาณข้อมูลด้วยโครงสร้างข้อมูล Count-Min") อธิบายได้ดี แต่จะพยายามสรุปต่อไป ความชาญฉลาดของ CMS อยู่ในวิธีการเก็บตัวอย่าง:แทนที่จะติดตามแต่ละตัวอย่างที่ไม่ซ้ำกันอย่างอิสระ มันใช้ค่าแฮชของมัน ค่าแฮชของตัวอย่างถูกใช้เป็นดัชนีของอาร์เรย์ขนาดคงที่ (กำหนดพารามิเตอร์เป็น d ในกระดาษ) ของตัวนับ ด้วยการใช้ฟังก์ชันแฮช (พารามิเตอร์ w) ที่แตกต่างกันหลายฟังก์ชันและอาร์เรย์ที่เกี่ยวข้อง ภาพสเก็ตช์จะจัดการกับการชนกันของแฮชที่พบขณะค้นหาโครงสร้างโดยเลือกค่าต่ำสุดจากตัวนับที่เกี่ยวข้องทั้งหมดสำหรับตัวอย่าง
มีการเรียกตัวอย่าง ดังนั้น มาทำสเก็ตช์ง่ายๆ เพื่อแสดงการทำงานภายในของโครงสร้างข้อมูล เพื่อให้ร่างภาพเรียบง่าย เราจะใช้ค่าพารามิเตอร์ขนาดเล็ก เราจะตั้งค่า w เป็น 3 ซึ่งหมายความว่าเราจะใช้ฟังก์ชันแฮชสามฟังก์ชัน – แทน h1, h2 และ h3 ตามลำดับ และ d ถึง 4 ในการจัดเก็บตัวนับของสเก็ตช์ เราจะใช้อาร์เรย์ 3×4 ที่มีทั้งหมด 12 องค์ประกอบเริ่มต้นเป็น 0
ตอนนี้เราสามารถตรวจสอบว่าเกิดอะไรขึ้นเมื่อมีการเพิ่มตัวอย่างลงในแบบร่าง สมมติว่าตัวอย่างมาถึงทีละรายการและแฮชสำหรับตัวอย่างแรกซึ่งแสดงเป็น s1 คือ:h1(s1) =1, h2(s1) =2 และ h3(s1) =3 ในการบันทึก s1 ในแบบร่าง เรา จะเพิ่มตัวนับของฟังก์ชันแฮชแต่ละตัวที่ดัชนีที่เกี่ยวข้องขึ้น 1 ตารางต่อไปนี้แสดงสถานะเริ่มต้นและสถานะปัจจุบันของอาร์เรย์:

แม้ว่าจะมีเพียงตัวอย่างเดียวในสเก็ตช์ แต่เราก็สามารถสืบค้นได้อย่างมีประสิทธิภาพ โปรดจำไว้ว่าจำนวนการสังเกตสำหรับตัวอย่างคือค่าต่ำสุดของตัวนับทั้งหมด ดังนั้นสำหรับ s1 จะได้มาโดย:
min(array[1][h1(s1)], array[2][h2(s1)], array[3][h3(s1)]) = แบบร่างยังตอบคำถามเกี่ยวกับตัวอย่างที่ยังไม่ได้เพิ่ม สมมติว่า h1 (ส2 ) =4, ชั่วโมง2 (ส2 ) =4, ชั่วโมง3 (ส2 ) =4 โปรดทราบว่าการสืบค้น s2 จะคืนค่าผลลัพธ์เป็น 0 มาต่อกันที่ s2 และ3 (h1 (ส3 ) =1, ชั่วโมง2 (ส3 ) =1, ชั่วโมง3 (ส3 ) =1) ให้ร่างโดยให้ผลดังนี้:
min(array[1][1], array[2][2], array[3][3]) =
min(1,1,1) = 1

ในตัวอย่างที่ประดิษฐ์ขึ้นของเรา แฮชของตัวอย่างเกือบทั้งหมดจะจับคู่กับตัวนับที่ไม่ซ้ำกัน โดยมีข้อยกเว้นประการหนึ่งคือการชนกันของ h1(s1) และ h1(s3) เนื่องจากแฮชทั้งสองเหมือนกัน ตัวนับที่ 1 ของ h1 จึงมีค่า 2 เนื่องจากแบบร่างเลือกค่าต่ำสุดของตัวนับทั้งหมด การสอบถามสำหรับ s1 และ s3 ยังคงส่งคืนผลลัพธ์ที่ถูกต้องเป็น 1 อย่างไรก็ตาม เมื่อมีการชนกันมากพอ เกิดขึ้น ผลลัพธ์ของข้อความค้นหาจะแม่นยำน้อยลง
พารามิเตอร์สองตัวของ CMS คือ w และ d กำหนดข้อกำหนดด้านพื้นที่/เวลา รวมถึงความน่าจะเป็นและค่าสูงสุดของข้อผิดพลาด วิธีที่ง่ายกว่าในการเริ่มต้นร่างคือการจัดเตรียมความน่าจะเป็นและขีดสูงสุดของข้อผิดพลาด เพื่อให้สามารถหาค่าที่ต้องการสำหรับ w และ d การทำ Parallelization เป็นไปได้เพราะสามารถรวม sub-sketches จำนวนเท่าใดก็ได้เป็นผลรวมของอาร์เรย์ ตราบใดที่พารามิเตอร์เดียวกันและฟังก์ชันแฮชถูกใช้ในการสร้าง
ข้อสังเกตบางประการเกี่ยวกับร่าง Count-min
ประสิทธิภาพของ Count Min Sketch สามารถแสดงให้เห็นได้โดยการตรวจสอบข้อกำหนด ความซับซ้อนของพื้นที่ของ CMS คือผลคูณของ w, d และความกว้างของตัวนับที่ใช้ ตัวอย่างเช่น ภาพสเก็ตช์ที่มีอัตราความผิดพลาด 0.01% ที่ความน่าจะเป็น 0.01% ถูกสร้างขึ้นโดยใช้ฟังก์ชันแฮช 10 ฟังก์ชันและอาร์เรย์ 2,000 ตัวนับ สมมติว่าใช้ตัวนับ 16 บิต ความต้องการหน่วยความจำโดยรวมของผลลัพธ์ของโครงสร้างข้อมูลนาฬิกาที่ 40KB (จำเป็นต้องใช้ไบต์เพิ่มเติมสองสามตัวสำหรับการจัดเก็บจำนวนการสังเกตทั้งหมดและตัวชี้สองสามตัว) ด้านการคำนวณอื่นๆ ของภาพสเก็ตช์นั้นน่าพึงพอใจเช่นเดียวกัน เนื่องจากฟังก์ชันแฮชนั้นผลิตและคำนวณได้ราคาถูก การเข้าถึงโครงสร้างข้อมูลไม่ว่าจะสำหรับการอ่านหรือการเขียน ก็ยังดำเนินการในเวลาคงที่เช่นกัน
CMS มีอะไรมากกว่านั้น ผู้เขียนร่างยังได้แสดงให้เห็นว่าสามารถใช้เพื่อตอบคำถามอื่นที่คล้ายคลึงกันได้อย่างไร ซึ่งรวมถึงการประมาณค่าเปอร์เซ็นไทล์และการระบุผู้โจมตีหนัก (รายการบ่อย) แต่อยู่นอกขอบเขตสำหรับโพสต์นี้
CMS เป็นภาพร่างที่ยอดเยี่ยมอย่างแน่นอน แต่มีอย่างน้อยสองสิ่งที่ขัดขวางไม่ให้เกิดความสมบูรณ์แบบ การจองครั้งแรกของฉันเกี่ยวกับ CMS คือมันสามารถลำเอียงได้ และด้วยเหตุนี้จึงประเมินความถี่ของตัวอย่างสูงเกินไปด้วยการสังเกตจำนวนเล็กน้อย อคติของ CMS เป็นที่รู้จักกันดีและมีการแนะนำการปรับปรุงหลายอย่าง ล่าสุดคือ Count Min Log Sketch (“การนับโดยประมาณด้วยตัวนับโดยประมาณ” จาก G. Pitel และ G. Fouquier) ซึ่งแทนที่การลงทะเบียนเชิงเส้นของ CMS ด้วยลอการิทึมเพื่อลดข้อผิดพลาดสัมพัทธ์และอนุญาตให้นับสูงขึ้นโดยไม่เพิ่มความกว้าง ของเคาน์เตอร์รีจิสเตอร์
ในขณะที่ทุกคนแชร์การจองข้างต้น (แม้ว่าจะเฉพาะผู้ที่ทำโครงสร้างข้อมูลเท่านั้น) การจองครั้งที่สองของฉันนั้นเป็นเอกสิทธิ์ของชุมชน Redis ในการอธิบาย ฉันจะต้องแนะนำ Redis Modules
โมดูล Redis
โมดูล Redis ได้รับการเปิดเผยเมื่อต้นปีนี้ที่ RedisConf โดย antirez และทำให้โลกของเรากลับหัวกลับหางอย่างแท้จริง ไม่มีอะไรมากหรือน้อยไปกว่าไลบรารีไดนามิกที่เซิร์ฟเวอร์โหลดได้ โมดูลอนุญาตให้ผู้ใช้ Redis เคลื่อนที่ได้เร็วกว่า Redis เองและไปในที่ที่ไม่เคยฝันถึงมาก่อน และในขณะที่โพสต์นี้ไม่ใช่การแนะนำว่าโมดูลคืออะไรหรือต้องสร้างอย่างไร แต่บทความนี้เป็น (เช่นเดียวกับโพสต์นี้ และการสัมมนาผ่านเว็บนี้)
มีเหตุผลหลายประการที่ฉันต้องการเขียนโมดูล Count Min Sketch Redis นอกเหนือจากประโยชน์สูงสุด ส่วนหนึ่งเป็นประสบการณ์การเรียนรู้ และอีกส่วนหนึ่งเป็นการประเมินโมดูล API แต่โดยส่วนใหญ่ เป็นเรื่องสนุกมากที่ได้จำลองโครงสร้างข้อมูลใหม่ใน Redis โมดูลนี้มีอินเทอร์เฟซ Redis สำหรับเพิ่มการสังเกตไปยังแบบร่าง การสืบค้น และการรวมภาพร่างหลายๆ ภาพเป็นหนึ่งเดียว
โมดูลจัดเก็บข้อมูลของสเก็ตช์ใน Redis String และใช้การเข้าถึงหน่วยความจำโดยตรง (DMA) สำหรับการจับคู่เนื้อหาของคีย์กับโครงสร้างข้อมูลภายใน ฉันยังไม่ได้ทำการวัดประสิทธิภาพที่ละเอียดถี่ถ้วนกับมัน แต่ความประทับใจแรกเริ่มของฉันจากการทดสอบในเครื่องคือมันมีประสิทธิภาพเทียบเท่ากับคำสั่ง Redis หลักใดๆ เช่นเดียวกับโมดูลอื่นๆ ของเรา countminsketch เป็นโอเพ่นซอร์ส และฉันขอแนะนำให้คุณลองใช้และแฮ็คมัน
ก่อนออกจากระบบ ฉันต้องการรักษาสัญญาและแชร์การจองเฉพาะ Redis เกี่ยวกับ CMS ปัญหา ซึ่งใช้กับแบบร่างและโครงสร้างข้อมูลอื่นๆ ด้วย คือ CMS ต้องการให้คุณตั้งค่า/เริ่มต้น/สร้างมันก่อนที่จะใช้งาน จำเป็นต้องมีขั้นตอนการเริ่มต้นที่จำเป็น เช่น การตั้งค่าพารามิเตอร์ CMS ทำลายรูปแบบพื้นฐานของ Redis อย่างหนึ่ง—ไม่จำเป็นต้องประกาศโครงสร้างข้อมูลอย่างชัดเจนก่อนใช้งาน เนื่องจากสามารถสร้างได้ตามความต้องการ เพื่อให้โมดูลดูเหมือน Redis-ish มากขึ้นและหลีกเลี่ยงรูปแบบการต่อต้านนั้น โมดูลจะใช้ค่าพารามิเตอร์เริ่มต้นเมื่อร่างใหม่ถูกบอกเป็นนัยโดยนัย (เช่น การใช้คำสั่ง CMS.ADD บนคีย์ที่ไม่มีอยู่) แต่ยังอนุญาตให้สร้างใหม่ สเก็ตช์เปล่าพร้อมพารามิเตอร์ที่กำหนด
โครงสร้างข้อมูลความน่าจะเป็นหรือแบบร่างเป็นเครื่องมือที่น่าทึ่งที่ช่วยให้เราติดตามการเติบโตของข้อมูลขนาดใหญ่และการหดตัวของงบประมาณเวลาแฝงด้วยวิธีที่มีประสิทธิภาพและแม่นยำเพียงพอ ภาพสเก็ตช์ทั้งสองภาพที่กล่าวถึงในโพสต์นี้ และอื่นๆ เช่น Bloom Filter และ T-digest กำลังกลายเป็นเครื่องมือที่ขาดไม่ได้อย่างรวดเร็วในคลังแสงของ Data Monger ที่ทันสมัย โมดูลช่วยให้คุณขยาย Redis ด้วยประเภทข้อมูลที่กำหนดเองและคำสั่งที่ทำงานด้วยความเร็วดั้งเดิมและเข้าถึงข้อมูลในเครื่องได้ ความเป็นไปได้ไม่มีที่สิ้นสุดและไม่มีอะไรที่เป็นไปไม่ได้
ต้องการเรียนรู้เพิ่มเติมเกี่ยวกับโมดูล Redis และวิธีการพัฒนาหรือไม่ มีโครงสร้างข้อมูลที่คุณต้องการอภิปรายหรือเพิ่มใน Redis หรือไม่ ไม่ว่าจะเป็นความน่าจะเป็นหรือไม่ อย่าลังเลที่จะติดต่อฉันด้วยอะไรก็ได้ที่บัญชี Twitter ของฉันหรือทางอีเมล – ฉันว่างมาก 🙂
