Pandas เป็นหนึ่งในไลบรารี่ python ที่ได้รับความนิยมมากที่สุดสำหรับวิทยาศาสตร์ข้อมูลและการวิเคราะห์ ห้องสมุด Pandas ใช้สำหรับการจัดการ วิเคราะห์ และทำความสะอาดข้อมูล เป็นนามธรรมระดับสูงเหนือ NumPy ระดับต่ำซึ่งเขียนในภาษา C ล้วนๆ ในส่วนนี้ เราจะกล่าวถึงสิ่งที่สำคัญที่สุด (ที่ใช้บ่อยที่สุด) ที่เราจำเป็นต้องรู้ในฐานะนักวิเคราะห์หรือนักวิทยาศาสตร์ข้อมูล
การติดตั้งไลบรารี่
เราสามารถติดตั้งไลบรารีที่จำเป็นได้โดยใช้ pip เพียงรันคำสั่งด้านล่างบนเทอร์มินัลคำสั่งของคุณ:
pip intall แพนด้า
ดาต้าเฟรมและซีรีส์
อันดับแรก เราต้องเข้าใจโครงสร้างข้อมูลพื้นฐานหลักสองประการของแพนด้า .i.e. ดาต้าเฟรมและซีรีส์ เราจำเป็นต้องมีความเข้าใจอย่างถ่องแท้เกี่ยวกับโครงสร้างข้อมูลทั้งสองนี้เพื่อที่จะควบคุมแพนด้าได้
ซีรีส์
Series เป็นอ็อบเจกต์ที่คล้ายกับรายการประเภท python built-in แต่แตกต่างจากมัน เพราะมันมีความเกี่ยวข้องกับ lable กับแต่ละองค์ประกอบหรือดัชนี
>>> นำเข้าแพนด้าเป็น pd>>> my_series =pd.Series([12, 24, 36, 48, 60, 72, 84])>>> my_series0 121 242 363 484 605 726 84dtype:int64ในผลลัพธ์ข้างต้น 'ดัชนี' จะอยู่ทางด้านซ้ายและ 'ค่า' ทางด้านขวา นอกจากนี้ แต่ละอ็อบเจ็กต์ Series มีประเภทข้อมูล (dtype) ในกรณีของเราคือ int64
เราสามารถดึงองค์ประกอบด้วยหมายเลขดัชนี:
>> my_series[6]84เพื่อให้ดัชนี (ป้ายกำกับ) ชัดเจน ให้ใช้:
>>> my_series =pd.Series([12, 24, 36, 48, 60, 72, 84], index =['ind0', 'ind1', 'ind2', 'ind3', 'ind4' , 'ind5', 'ind6'])>>> my_seriesind0 12ind1 24ind2 36ind3 48ind4 60ind5 72ind6 84dtype:int64นอกจากนี้ยังง่ายต่อการดึงข้อมูลองค์ประกอบหลายอย่างโดยใช้ดัชนีหรือกำหนดกลุ่ม:
>>> my_series[['ind0', 'ind3', 'ind6']]ind0 12ind3 48ind6 84dtype:int64>>> my_series[['ind0', 'ind3', 'ind6']] =36>>> my_seriesind0 36ind1 24ind2 36ind3 36ind4 60ind5 72ind6 36dtype:int64การกรองและการคำนวณทางคณิตศาสตร์ทำได้ง่ายเช่นกัน:
>>> my_series[my_series>24]ind0 36ind2 36ind3 36ind4 60ind5 72ind6 36dtype:int64>>> my_series[my_series <24] * 2Series([], dtype:int64)>>> my_seriesind0 36ind1 72ind2 36ind3 36ind4 60ind 36dtype:int64>>>ด้านล่างนี้คือการดำเนินการทั่วไปอื่นๆ ในซีรีส์
>>> #ทำงานเป็นพจนานุกรม>>> my_series1 =pd.Series({'a':9, 'b':18, 'c':27, 'd':36})>>> my_series1a 9b 18c 27d 36dtype:int64>>> คุณลักษณะ #Label>>> my_series1.name ='Numbers'>>>> my_series1.index.name ='letters'>>> my_series1lettersa 9b 18c 27d 36Name:ตัวเลข dtype:int64>>> #chaning Index>>> my_series1.index =['w', 'x', 'y', 'z']>>> my_series1w 9x 18y 27z 36Name:ตัวเลข, dtype:int64>>>ดาต้าเฟรม
DataFrame ทำหน้าที่เหมือนตารางเนื่องจากมีแถวและคอลัมน์ แต่ละคอลัมน์ใน DataFrame เป็นอ็อบเจ็กต์ Series และแถวประกอบด้วยองค์ประกอบภายใน Series
สามารถสร้าง DataFrame ได้โดยใช้ Python dicts ในตัว:
>>> df =pd.DataFrame({ 'Country':['China', 'India', 'Indonesia', 'Pakistan'], 'Population':[1420062022, 1368737513, 269536482, 204596442], ' พื้นที่' :[9388211, 2973190, 1811570, 770880]})>>> df Area Country Population0 9388211 ประเทศจีน 14200620221 2973190 อินเดีย 13687375132 1811570 อินโดนีเซีย 2695364823 770880 ปากีสถาน 204596442>>> df['Country']0 China1 India2 Indonesia3 PakistanName:Country, dtype:object>>> df.columnsIndex(['Area', 'Country', 'Population'], dtype='object')>>> df.indexRangeIndex(start=0, stop=4, step=1)>>>การเข้าถึงองค์ประกอบ
มีหลายวิธีในการจัดทำดัชนีแถวอย่างชัดเจน
>>> df =pd.DataFrame({ 'Country':['China', 'India', 'Indonesia', 'Pakistan'], 'Population':[1420062022, 1368737513, 269536482, 204596442], ' Landarea' :[9388211, 2973190, 1811570, 770880]}, index =['CHA', 'IND', 'IDO', 'PAK'])>>> dfCountry Landarea PopulationCHA ประเทศจีน 9388211 1420062022IND อินเดีย 2973190 1368737513IDO อินโดนีเซีย 1811570 269536482PAK ปากีสถาน 770880 204596442>>> df.index =['CHI', 'IND', 'IDO', 'PAK']>>> df.index.name ='รหัสประเทศ'>>>> dfCountry Landarea PopulationCountry CodeCHI ประเทศจีน 9388211 1420062022IND อินเดีย 2973190 1368737513IDO อินโดนีเซีย 1811570 269536482PAK ปากีสถาน 770880 204596442>>> df['Country']รหัสประเทศCHI ประเทศจีนIND อินเดียIDO อินโดนีเซียPAK PakistanName:ประเทศ dtype:วัตถุการเข้าถึงแถวโดยใช้ดัชนีสามารถทำได้หลายวิธี
- การใช้ .loc และการระบุป้ายกำกับดัชนี
- การใช้ .iloc และระบุหมายเลขดัชนี
>>> df.loc['IND']Country IndiaLandarea 2973190Population 1368737513Name:IND, dtype:object>>> df.iloc[1]Country IndiaLandarea 2973190ประชากร 1368737513Name:IND, dtype:object>>>>>> df .loc[['CHI', 'IND'], 'Population']รหัสประเทศCHI 1420062022IND 1368737513ชื่อ:ประชากร, dtype:int64
การอ่านและการเขียนไฟล์
Pandas รองรับรูปแบบไฟล์ยอดนิยมมากมาย เช่น CSV, XML, HTML, Excel, SQL, JSON และอีกมากมาย โดยทั่วไปจะใช้รูปแบบไฟล์ CSV
หากต้องการอ่านไฟล์ csv เพียงเรียกใช้:
>>> df =pd.read_csv('GDP.csv', sep =',') อาร์กิวเมนต์ที่มีชื่อ sep ชี้ไปที่อักขระตัวคั่นในไฟล์ CSV ชื่อ GDP.csv
การรวมและการจัดกลุ่ม
เพื่อจัดกลุ่มข้อมูลในแพนด้า เราสามารถใช้เมธอด .groupby ในการสาธิตการใช้การรวมและการจัดกลุ่มในแพนด้า ฉันใช้ชุดข้อมูลไททานิค คุณสามารถค้นหาได้จากลิงก์ด้านล่าง:
https://yadi.sk/d/TfhJdE2k3EyALt
>>> titanic_df =pd.read_csv('titanic.csv')>>> print(titanic_df.head())PassengerID Name PClass Age \0 1 Allen, Miss Elisabeth Walton 1st 29.001 2 Allison, Miss Helen Loraine 1st 2.002 3 Allison, Mr Hudson Joshua Creighton 1st 30.003 4 Allison, Mrs Hudson JC (Bessie Waldo Daniels) 1st 25.004 5 Allison, Master Hudson Trevor 1st 0.92 Sex Survived SexCode0 หญิง 1 11 หญิง 0 12 ชาย 0 03 หญิง 0 14 ชาย 1 0>>> มาคำนวณกันว่าผู้โดยสาร (หญิงและชาย) รอดชีวิตได้กี่คน เราจะใช้ .groupby
>>> พิมพ์(titanic_df.groupby(['Sex', 'Survived'])['PassengerID'].count())Sex Survivedfemale 0 154 1 308male 0 709 1 142Name:PassengerID, dtype:int64ข้อมูลด้านบนตามชั้นโดยสาร:
>>> print(titanic_df.groupby(['PClass', 'Survived'])['PassengerID'].count())PClass Survived* 0 11st 0 129 1 1932nd 0 160 1 1193rd 0 573 1 138Name:PassengerID, dtype:int64การวิเคราะห์อนุกรมเวลาโดยใช้แพนด้า
Pandas ถูกสร้างขึ้นเพื่อวิเคราะห์ข้อมูลอนุกรมเวลา เพื่อเป็นการแสดงให้เห็น ฉันได้ใช้ราคาหุ้นอเมซอน 5 ปี สามารถดาวน์โหลดได้จากลิงค์ด้านล่าง
https://finance.yahoo.com/quote/AMZN/history?period1=1397413800&period2=1555180200&interval=1mo&filter=history&frequency=1mo
>>> นำเข้าแพนด้าเป็น pd>>> amzn_df =pd.read_csv('AMZN.csv', index_col='Date', parse_dates=True)>>> amzn_df =amzn_df.sort_index()>>> พิมพ์ ( amzn_df.info())DatetimeIndex:62 รายการ, 2014-04-01 ถึง 2019-04-12 คอลัมน์ข้อมูล (ทั้งหมด 6 คอลัมน์):เปิด 62 วัตถุที่ไม่ใช่ค่าว่าง สูง 62 ไม่ใช่- null objectLow 62 non-null objectClose 62 non-null objectAdj ปิด 62 non-null objectVolume 62 non-null objectdtypes:object(6)การใช้หน่วยความจำ:1.9+ KBNone ด้านบน เราได้สร้าง DataFRame ด้วยคอลัมน์ DatetimeIndex ตาม Date แล้วจึงจัดเรียง
และราคาปิดเฉลี่ยคือ
>>> amzn_df.loc['2015-04', 'Close'].mean()421.779999การแสดงภาพ
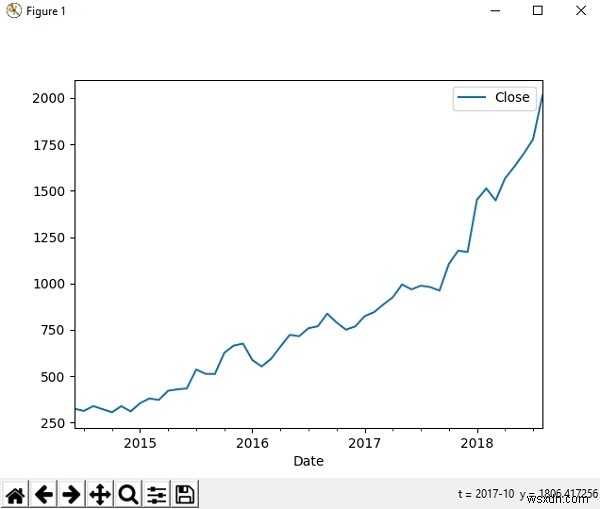
เราสามารถใช้ไลบรารี่ matplotlib เพื่อแสดงภาพแพนด้าได้ มาดูชุดข้อมูลย้อนหลังของหุ้น Amazon และดูการเคลื่อนไหวของราคาในช่วงเวลาหนึ่งบนกราฟ
>>> นำเข้า matplotlib.pyplot เป็น plt>>> df =pd.read_csv('AMZN.csv', index_col ='Date' , parse_dates =True)>>>> new_df =df.loc['2014-06 ':'2018-08', ['ปิด']]>>> new_df=new_df.astype(float)>>>> new_df.plot()>>> plt. แสดง()