
สำหรับการวิเคราะห์ข้อมูล การวิเคราะห์ข้อมูลเชิงสำรวจ (EDA) ต้องเป็นก้าวแรกของคุณ การวิเคราะห์ข้อมูลเชิงสำรวจช่วยให้เรา -
-
เพื่อให้เข้าใจถึงชุดข้อมูล
-
ทำความเข้าใจกับโครงสร้างพื้นฐาน
-
ดึงข้อมูลพารามิเตอร์และความสัมพันธ์ที่สำคัญที่เก็บไว้ระหว่างกัน
-
ทดสอบสมมติฐานพื้นฐาน
ทำความเข้าใจ EDA โดยใช้ชุดข้อมูลตัวอย่าง
เพื่อให้เข้าใจ EDA โดยใช้ python เราสามารถนำข้อมูลตัวอย่างได้โดยตรงจากเว็บไซต์ใดๆ หรือจากดิสก์ในเครื่องของคุณ ฉันกำลังนำข้อมูลตัวอย่างจาก UCI Machine Learning Repository ซึ่งเปิดเผยต่อสาธารณะเกี่ยวกับชุดข้อมูลคุณภาพไวน์สีแดง และพยายามดึงข้อมูลเชิงลึกจำนวนมากเกี่ยวกับชุดข้อมูลโดยใช้ EDA
import pandas as pd
df = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv")
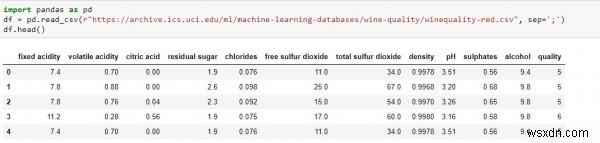
df.head() การเรียกใช้สคริปต์ด้านบนในสมุดบันทึก jupyter จะให้ผลลัพธ์ดังนี้ -
เริ่มต้นด้วย
-
ขั้นแรก นำเข้าไลบรารี่ที่จำเป็น แพนด้าในกรณี
-
อ่านไฟล์ csv โดยใช้ฟังก์ชัน read_csv() ของไลบรารี pandas และข้อมูลแต่ละรายการจะถูกคั่นด้วยตัวคั่น ";" ในชุดข้อมูลที่กำหนด
-
ส่งคืนการสังเกตห้ารายการแรกจากชุดข้อมูลโดยใช้ฟังก์ชัน ".head" ที่จัดทำโดยไลบรารีแพนด้า เราสามารถรับการสังเกตห้าครั้งสุดท้ายในทำนองเดียวกันโดยใช้ฟังก์ชัน “.tail()” ของไลบรารีแพนด้า
เราสามารถรับจำนวนแถวและคอลัมน์ทั้งหมดจากชุดข้อมูลโดยใช้ “.shape” ดังรูปด้านล่าง -
df.shape

เพื่อค้นหาว่าคอลัมน์ทั้งหมดประกอบด้วยอะไร ประเภทใด และมีค่าใดอยู่ในนั้นหรือไม่ โดยใช้ฟังก์ชัน info()
df.info()
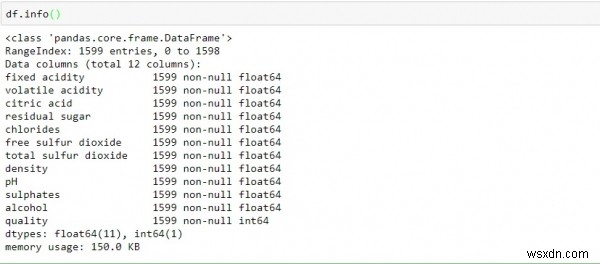
จากการสังเกตข้อมูลข้างต้น เราสามารถสรุปได้ −
-
ข้อมูลมีค่าทศนิยมเป็นจำนวนเต็มเท่านั้น
-
ตัวแปรคอลัมน์ทั้งหมดไม่เป็นค่าว่าง (ไม่มีค่าว่างหรือค่าขาดหายไป)
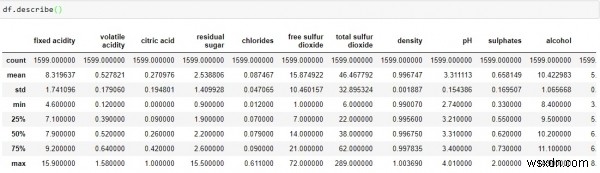
ฟังก์ชันที่มีประโยชน์อีกอย่างของแพนด้าคือ description() ซึ่งให้การนับ ค่าเฉลี่ย ส่วนเบี่ยงเบนมาตรฐาน ค่าต่ำสุดและสูงสุด และปริมาณข้อมูล
df.describe()
-
จากข้อมูลข้างต้น เราสามารถสรุปได้ว่าค่าเฉลี่ยของแต่ละคอลัมน์น้อยกว่าค่ามัธยฐาน (50%) ในคอลัมน์ดัชนี
-
มีความแตกต่างอย่างมากระหว่าง 75% และค่าสูงสุดของตัวทำนาย "น้ำตาลตกค้าง", "ซัลเฟอร์ไดออกไซด์อิสระ" และ "ซัลเฟอร์ไดออกไซด์ทั้งหมด"
-
เหนือการสังเกต 2 ครั้ง ให้ข้อบ่งชี้ว่ามีค่าสุดขั้ว- ความเบี่ยงเบนในชุดข้อมูลของเรา
ข้อมูลเชิงลึกที่สำคัญสองสามข้อที่เราได้จากตัวแปรตามมีดังนี้ -
df.quality.unique()

-
ในระดับคะแนน "คุณภาพ" 1 อยู่ที่ด้านล่าง .i.e. ยากจนและ 10 มาที่ด้านบน .i.e. ดีที่สุด
-
จากด้านบน เราสามารถสรุปได้ว่า ไม่มีคะแนนการสังเกต 1(แย่) 2 และ 9 10 (ดีที่สุด) คะแนนทั้งหมดอยู่ระหว่าง 3 ถึง 8
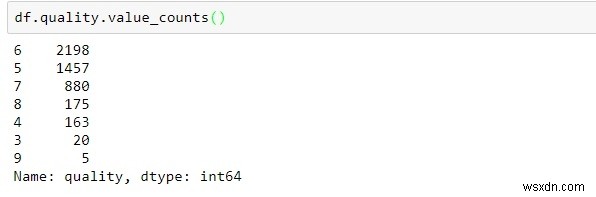
df.quality.value_counts()
-
ข้อมูลที่ประมวลผลด้านบนให้ข้อมูลเกี่ยวกับการนับคะแนนสำหรับคะแนนคุณภาพแต่ละรายการโดยเรียงจากมากไปน้อย
-
คุณภาพส่วนใหญ่อยู่ในช่วง 5-7
-
มีการสังเกตน้อยที่สุดใน 3 และ 6 หมวดหมู่
การแสดงข้อมูล
ในการตรวจสอบค่าที่หายไป -
เราสามารถตรวจสอบค่าที่หายไปได้ในชุดข้อมูล csv สีขาว-วิสกี้ของเราด้วยความช่วยเหลือของห้องสมุด seaborn ด้านล่างนี้เป็นรหัสสำหรับกรอกว่า -
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
sns.set()
df = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv", sep=";")
sns.heatmap(df.isnull(), cbar=False, yticklabels=False, cmap='viridis') ผลลัพธ์
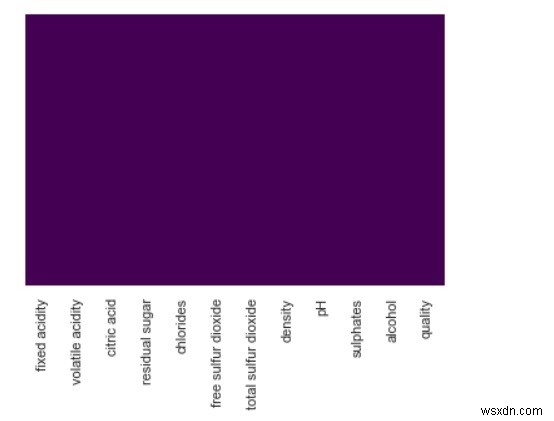
-
จากด้านบน เราจะเห็นว่าไม่มีค่าที่ขาดหายไปในชุดข้อมูล เผื่อว่าถ้ามี เราคงได้เห็นตัวเลขที่แสดงด้วยเฉดสีต่างๆ บนพื้นหลังสีม่วง
-
ด้วยชุดข้อมูลที่แตกต่างกันซึ่งมีค่าที่หายไป และคุณจะสังเกตเห็นความแตกต่าง
เพื่อตรวจสอบความสัมพันธ์
ในการตรวจสอบความสัมพันธ์ระหว่างค่าต่างๆ ของชุดข้อมูล ให้แทรกโค้ดด้านล่างในชุดข้อมูลที่มีอยู่ -
plt.figure(figsize=(8,4)) sns.heatmap(df.corr(),cmap='Greens',annot=False)
ผลลัพธ์
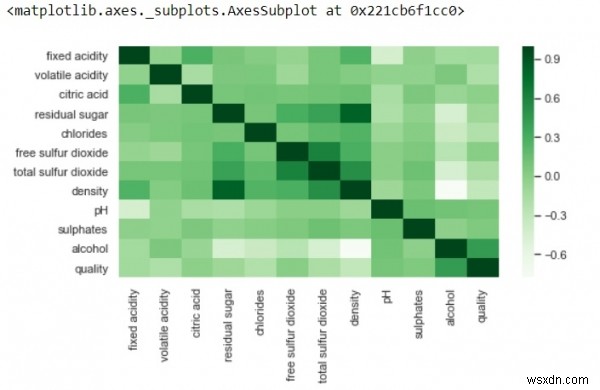
-
ด้านบน ความสัมพันธ์เชิงบวกจะแสดงด้วยเฉดสีเข้มและความสัมพันธ์เชิงลบด้วยเฉดสีที่อ่อนกว่า
-
เปลี่ยนค่าของ annot=True และผลลัพธ์จะแสดงค่าให้คุณเห็นว่าคุณลักษณะใดมีความสัมพันธ์ซึ่งกันและกันในเซลล์กริด
เราสามารถสร้างเมทริกซ์สหสัมพันธ์อื่นด้วย annot=True แก้ไขโค้ดของคุณโดยเพิ่มบรรทัดโค้ดด้านล่างลงในโค้ดที่มีอยู่ของเรา -
k = 12 cols = df.corr().nlargest(k, 'quality')['quality'].index cm = df[cols].corr() plt.figure(figsize=(8,6)) sns.heatmap(cm, annot=True, cmap = 'viridis')
ผลลัพธ์
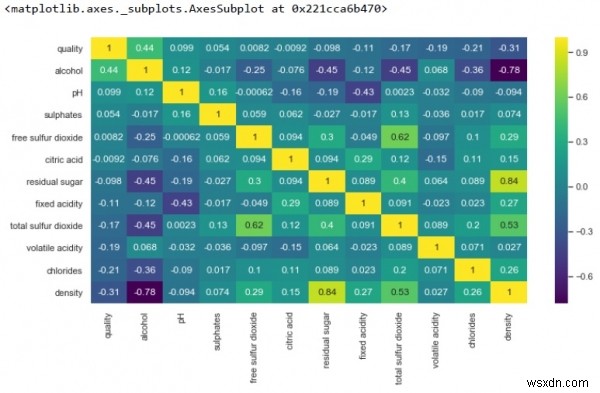
-
จากด้านบน เราจะเห็นได้ว่ามีความสัมพันธ์เชิงบวกที่แข็งแกร่งของความหนาแน่นกับน้ำตาลที่เหลือ อย่างไรก็ตาม มีความสัมพันธ์เชิงลบอย่างมากกับความหนาแน่นและแอลกอฮอล์
-
นอกจากนี้ยังไม่มีความสัมพันธ์ระหว่างซัลเฟอร์ไดออกไซด์อิสระกับคุณภาพ
