

Excel เป็นเครื่องมือที่ทรงพลังอย่างน่าประหลาดใจสำหรับงานการเรียนรู้ของเครื่องขั้นพื้นฐาน แม้ว่าจะไม่ใช่แพลตฟอร์มแมชชีนเลิร์นนิง แต่ก็สามารถใช้เพื่อสาธิตแนวคิด ML พื้นฐาน เช่น การถดถอยเชิงเส้นและการถดถอยโลจิสติกได้อย่างมีประสิทธิภาพ โดยใช้ฟังก์ชันในตัวและ Solver
ในบทช่วยสอนนี้ เราจะแสดงวิธีสร้างโมเดลการเรียนรู้ของเครื่องแบบน้ำหนักเบาใน Excel โดยใช้ Solver และสูตร
- การถดถอยเชิงเส้น: คาดการณ์ค่าต่อเนื่อง (รายได้จากการขาย ราคาบ้าน คะแนนทดสอบ ฯลฯ)
- การถดถอยโลจิสติก: คาดการณ์ผลลัพธ์ใช่/ไม่ใช่ (การซื้อของลูกค้า การผิดนัดชำระสินเชื่อ การวินิจฉัยทางการแพทย์ ผ่าน/ไม่ผ่าน ฯลฯ)
ข้อกำหนดเบื้องต้น:
- Microsoft Excel (แนะนำปี 2016 หรือใหม่กว่า)
- เปิดใช้งาน Solver Add-in
- ไปที่ ไฟล์ แท็บ>> เลือก ตัวเลือก >> เลือก ส่วนเสริม>> เลือก โปรแกรมเสริมของ Excel .
- คลิก ไป .
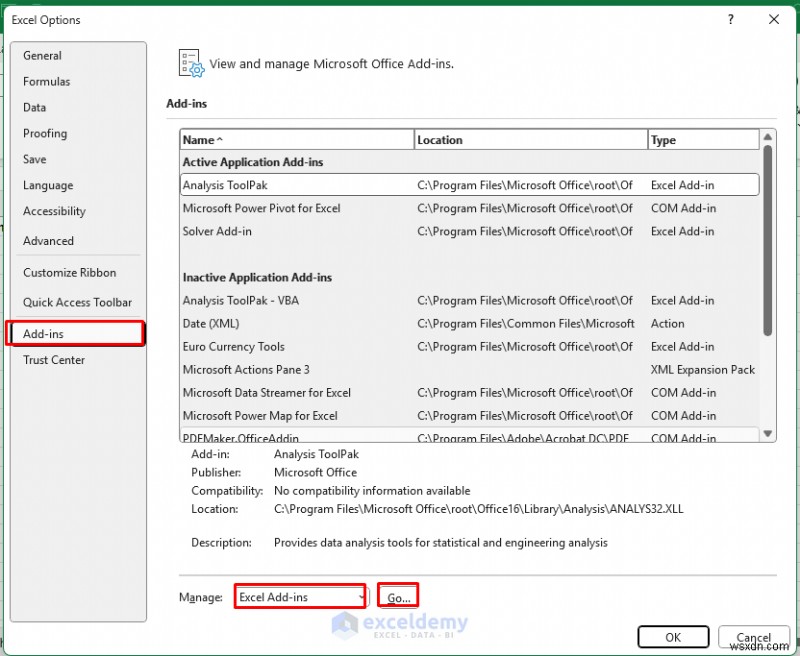
- เลือก Solver Add-in .
- คลิก ตกลง .
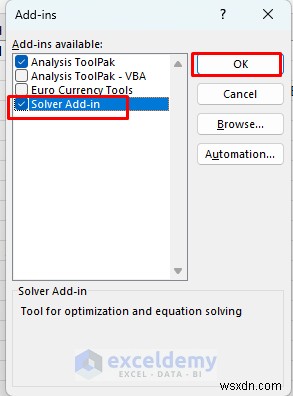
- ความเข้าใจพื้นฐานเกี่ยวกับแนวคิดการถดถอย
ส่วนที่ 1:โมเดลการถดถอยเชิงเส้น
การถดถอยเชิงเส้นจะค้นหาเส้นตรงที่ดีที่สุดในการทำนายค่าตัวเลขต่อเนื่องผ่านจุดข้อมูล เราจะจำลองสถานการณ์ทางธุรกิจอย่างง่ายโดยที่ค่าโฆษณา (X) คาดการณ์รายได้จากการขาย (Y) จุดข้อมูลแต่ละจุดแสดงถึงข้อมูลธุรกิจหนึ่งเดือน
ขั้นตอนที่ 1:การตั้งค่าข้อมูลตัวอย่าง
สร้างชุดข้อมูลที่สมจริงซึ่งแสดงความสัมพันธ์เชิงเส้นที่ชัดเจนระหว่างข้อมูลเข้า (ค่าโฆษณาเป็นพัน) และผลลัพธ์ (รายได้จากการขายเป็นพัน)
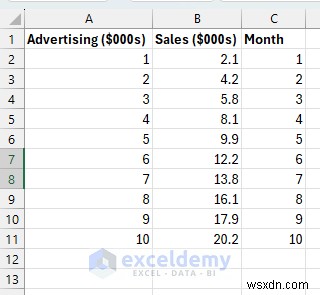
แต่ละแถวคือข้อมูลธุรกิจหนึ่งเดือน เมื่อค่าโฆษณาเพิ่มขึ้น รายได้จากการขายก็เพิ่มขึ้นเช่นกัน แต่ก็ไม่สมบูรณ์แบบ (มีความบังเอิญอยู่บ้าง ซึ่งเป็นเรื่องจริง)
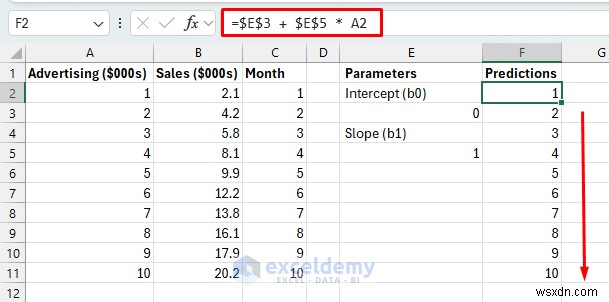
ขั้นตอนที่ 2:สร้างสูตรการทำนาย
ตั้งค่า “ปุ่ม” ทางคณิตศาสตร์ที่แบบจำลองของเราจะปรับเพื่อค้นหาเส้นที่ดีที่สุด ในการถดถอยเชิงเส้น เราจำเป็นต้องมีพารามิเตอร์สองตัว:
- สกัดกั้น (b0) :โดยที่เส้นตัดผ่านแกน Y (ยอดขายพื้นฐานพร้อมการโฆษณา $0)
- ความชัน (b1) :ยอดขายเพิ่มขึ้นเท่าใดสำหรับการโฆษณาที่เพิ่มขึ้นทุกๆ $1,000
ตั้งค่าพารามิเตอร์โมเดลในเซลล์แยก:
พารามิเตอร์โมเดล:
Predicted Y = b0 + b1 * X
- สกัดกั้น (b0)
- ค่าเริ่มต้น 0
- ความชัน (b1)
- ค่าเริ่มต้น 1
เราจะใช้สมการเชิงเส้นนี้เพื่อคาดการณ์ยอดขายตามค่าใช้จ่ายในการโฆษณา นี่คือแกนหลักของโมเดล และจะใช้จำนวนเงินโฆษณาและประมาณการยอดขายที่ควรจะเป็น
ความหมายทางคณิตศาสตร์:
- หาก b0 =0.5 และ b1 =2 ดังนั้นการใช้จ่าย 3,000 ดอลลาร์ในการโฆษณาจะคาดการณ์:0.5 + 2*3 =ยอดขาย 6.5,000 ดอลลาร์
- โมเดลเรียนรู้ค่าที่ดีที่สุดสำหรับ b0 และ b1 จากข้อมูล
สูตรการทำนาย:
- เลือกเซลล์และแทรกสูตรต่อไปนี้
- ลากสูตรนี้ลงไปที่ F11
ขั้นตอนที่ 4:คำนวณค่าคงเหลือและข้อผิดพลาด
วัดว่าการคาดการณ์ของเราผิดแค่ไหน นี่เป็นสิ่งสำคัญเนื่องจากโมเดลเรียนรู้โดยพยายามลดข้อผิดพลาดเหล่านี้ให้เหลือน้อยที่สุด
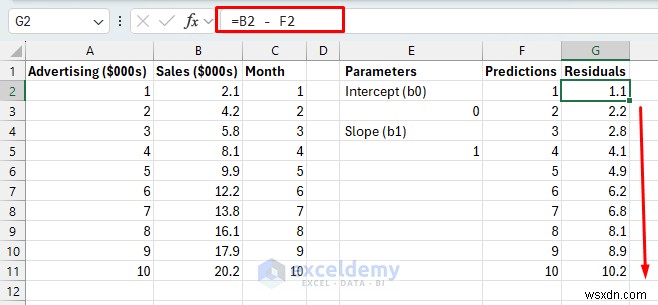
- คงเหลือ: ความแตกต่างระหว่างยอดขายจริงและยอดขายที่คาดการณ์ไว้ในแต่ละเดือน
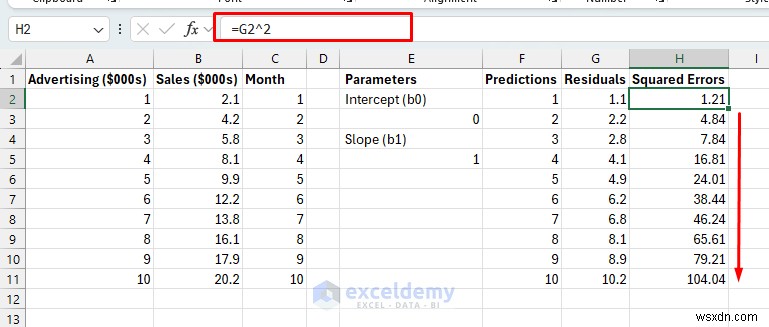
- ข้อผิดพลาดกำลังสอง: ส่วนที่เหลือยกกำลังสอง (เพื่อทำให้ข้อผิดพลาดทั้งหมดเป็นบวกและลงโทษข้อผิดพลาดขนาดใหญ่มากขึ้น)
คงเหลือ:
- ลากสูตรลงไปที่ G11
ข้อผิดพลาดกำลังสอง:
- ลากสูตรลงไปที่ H11
ขั้นตอนที่ 5:คำนวณการวัดข้อผิดพลาด
สร้างการวัดประสิทธิภาพของโมเดลที่มีความหมายทางธุรกิจ เมตริกเหล่านี้ช่วยให้เข้าใจว่าโมเดลนั้นดีเพียงพอสำหรับการใช้งานจริงหรือไม่
ตั้งค่าตัวชี้วัดหลักในพื้นที่ที่กำหนด:
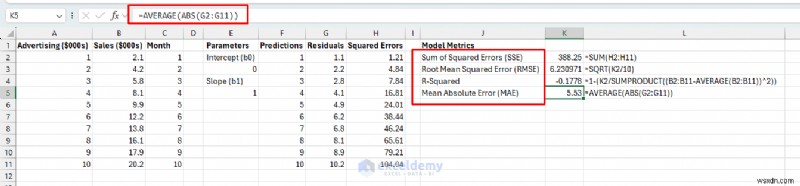
การวัดข้อผิดพลาด:
- ผลรวมของข้อผิดพลาดกำลังสอง (SSE): ข้อผิดพลาดทั้งหมดจากการคาดการณ์ทั้งหมด - ต่ำกว่าจะดีกว่า
- ข้อผิดพลาดรูทค่าเฉลี่ยกำลังสอง (RMSE): ข้อผิดพลาดโดยเฉลี่ยในหน่วยดั้งเดิม ($000) – ตีความได้ง่ายกว่า
- R-กำลังสอง: เปอร์เซ็นต์ของรูปแบบการขายที่อธิบายโดยการโฆษณา (0-100% ยิ่งสูงยิ่งดี)
=1-(K2/SUMPRODUCT((B2:B11-AVERAGE(B2:B11))^2))
- ค่าเฉลี่ยความคลาดเคลื่อนสัมบูรณ์ (MAE): ข้อผิดพลาดสัมบูรณ์โดยเฉลี่ย – มีความไวต่อค่าผิดปกติน้อยกว่า RMSE
ขั้นตอนที่ 6:ใช้ Solver เพื่อปรับพารามิเตอร์ให้เหมาะสม
ปล่อยให้ Excel ค้นหาค่าที่ดีที่สุดสำหรับจุดตัดและความชันโดยอัตโนมัติซึ่งจะช่วยลดข้อผิดพลาดในการคาดการณ์
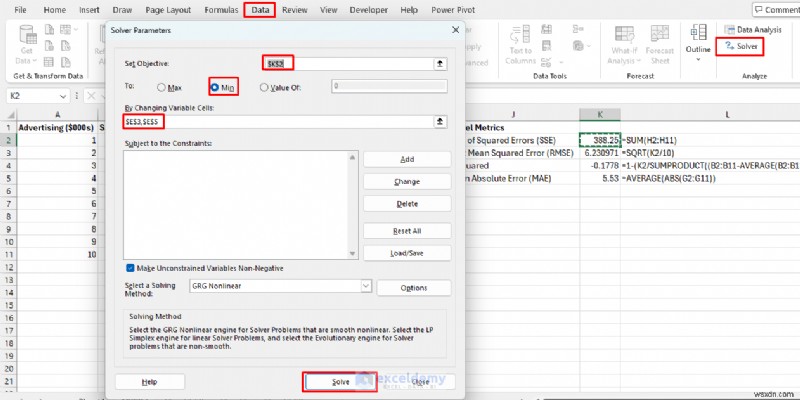
- ไปที่ ข้อมูล แท็บ>> เลือก ตัวแก้ปัญหา .
- กำหนดวัตถุประสงค์:K2 (เซลล์ SSE)
- ถึง:ขั้นต่ำ .
- โดยการเปลี่ยนเซลล์ตัวแปร:E3,E5 (พารามิเตอร์ของคุณ)
- คลิก แก้ปัญหา .
- คลิก ตกลง .
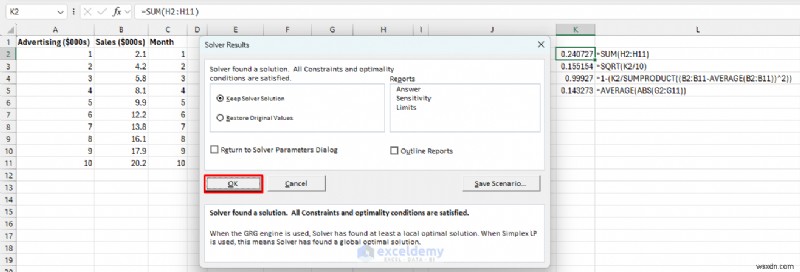
- ลองใช้ b0 และ b1 รวมกันหลายล้านแบบ
- คำนวณข้อผิดพลาดทั้งหมดสำหรับชุดค่าผสมแต่ละชุด
- ปรับไปเรื่อยๆ จนกว่าจะพบชุดค่าผสมที่มีข้อผิดพลาดน้อยที่สุด
- สิ่งนี้รวดเร็วและแม่นยำมากกว่าการคาดเดามาก

ขั้นตอนที่ 7:สร้างการแสดงภาพ
การตรวจสอบแบบจำลองด้วยสายตานั้นสมเหตุสมผล มาดูเส้นทำนายที่ส่งผ่านใกล้กับจุดข้อมูลส่วนใหญ่กัน
- เลือกคอลัมน์การโฆษณาและการขาย
- ไปที่ แทรก แท็บ>> จาก แผนภูมิ >> เลือก แผนภูมิกระจาย .
- คลิกขวาที่แผนภูมิ>> เลือก ข้อมูล >> เลือก เพิ่มซีรี่ส์ .
- ชื่อซีรี่ส์: เลือกเซลล์ F1
- ค่าซีรีส์ X: เลือกค่า X (เช่น B2:B11)
- ค่าซีรี่ส์ Y: คลิกและเลือกค่าที่ทำนายไว้ F2:F11
- จัดรูปแบบชุดการทำนายเป็นเส้น
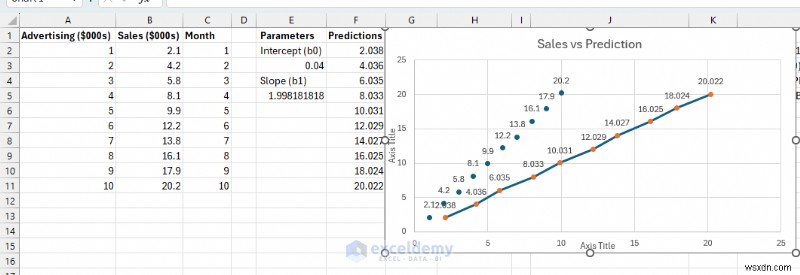
- เส้นคาดการณ์เป็นไปตามแนวโน้มทั่วไปของจุดข้อมูล
- คะแนนกระจัดกระจายรอบเส้น (ไม่ได้อยู่ด้านบนหรือด้านล่างทั้งหมด)
- ไม่มีรูปแบบที่ชัดเจนในสิ่งตกค้าง
ส่วนที่ 2:โมเดลการถดถอยโลจิสติก
การถดถอยโลจิสติกทำนายความน่าจะเป็นสำหรับการตัดสินใจใช่/ไม่ใช่ ต่างจากการถดถอยเชิงเส้นซึ่งทำนายตัวเลขที่แน่นอน การถดถอยแบบลอจิสติกทำนายความน่าจะเป็นของบางสิ่งที่เกิดขึ้น (0-100%)
ขั้นตอนที่ 1:เตรียมข้อมูลการจำแนกประเภทไบนารี
เรามาจำลองพฤติกรรมการซื้อของลูกค้ากันดีกว่า จากระดับรายได้ของลูกค้า (X) เราต้องการคาดการณ์ว่าพวกเขาจะซื้อผลิตภัณฑ์ระดับพรีเมียมของเรา (1) หรือไม่ (0) ซึ่งเป็นเรื่องปกติสำหรับการกำหนดเป้าหมายทางการตลาด การวินิจฉัยทางการแพทย์ หรือการตัดสินใจแบบไบนารี
ตั้งค่าข้อมูลสำหรับการถดถอยโลจิสติก:
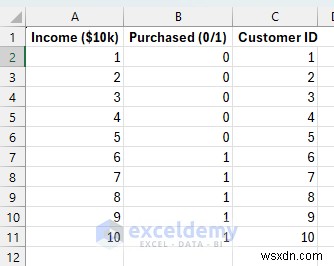
ระดับรายได้ของลูกค้า (ในหน่วย 10,000 ดอลลาร์) และการตัดสินใจซื้อ สังเกตว่าลูกค้าที่มีรายได้น้อย (1-5) มักจะไม่ซื้อ (0) ในขณะที่ลูกค้าที่มีรายได้สูง (6-10) มักจะซื้อ (1) สิ่งนี้สะท้อนถึงรูปแบบการซื้อที่สมจริง
ขั้นตอนที่ 2:สร้างสูตรการทำนายลอจิสติก
เริ่มต้นพารามิเตอร์โมเดลลอจิสติก:
ตั้งค่าพารามิเตอร์สำหรับฟังก์ชันลอจิสติก ต่างจากการถดถอยเชิงเส้น พารามิเตอร์เหล่านี้ทำงานผ่านการแปลงทางคณิตศาสตร์ที่ซับซ้อนมากขึ้น (ฟังก์ชันซิกมอยด์)
- สกัดกั้น (b0) :เลื่อนเกณฑ์ไปทางซ้ายหรือขวา (โดยที่มีความน่าจะเป็น 50%)
- ความชัน (b1) :ควบคุมระดับการเปลี่ยนแปลงจาก "ไม่น่าจะเป็นไปได้" เป็น "น่าจะเป็นไปได้"
- ค่าเริ่มต้น :เราเริ่มต้นด้วยการคาดเดาที่สมเหตุสมผล โปรแกรมแก้ปัญหาจะปรับให้เหมาะสม
พารามิเตอร์ลอจิสติก:
Probability = 1 / (1 + e^(-(b0 + b1×X)))
- สกัดกั้น (b0)
- -2 (ค่าเริ่มต้น)
- ความชัน (b1)
- 0.5 (ค่าเริ่มต้น)
สร้างสูตรการทำนายลอจิสติก:
แปลงผลรวมเชิงเส้นให้เป็นความน่าจะเป็นโดยใช้ฟังก์ชันซิกมอยด์ นี่คือความมหัศจรรย์ทางคณิตศาสตร์ที่ทำให้การทำนายอยู่ระหว่าง 0 ถึง 1
- การรวมเชิงเส้น :b0 + b1*X (เหมือนกับการถดถอยเชิงเส้น)
- การแปลงซิกมอยด์ :1/(1+e^(-(ผลรวมเชิงเส้น))) แปลงตัวเลขใดๆ ให้เป็นช่วง 0-1
- ผลลัพธ์ :เส้น S เรียบที่แสดงถึงความน่าจะเป็น หากความน่าจะเป็นคือ 0.7 แสดงว่ามีโอกาส 70% ที่ลูกค้ารายนี้จะซื้อ
การทำนายความน่าจะเป็น:
- การรวมเชิงเส้น:
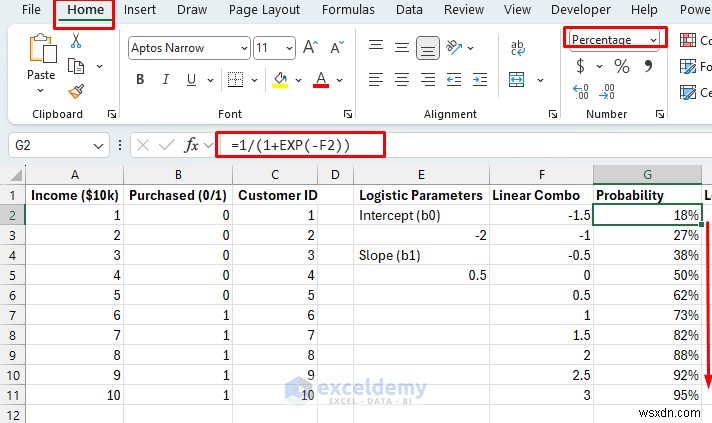
- การทำนายความน่าจะเป็น:
- จัดรูปแบบเซลล์เป็น เปอร์เซ็นต์ (%) .
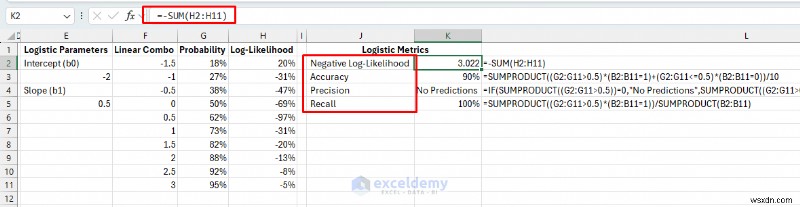
ขั้นตอนที่ 4:คำนวณบันทึก-ความน่าจะเป็น
วัดว่าการทำนายความน่าจะเป็นของเราตรงกับผลลัพธ์ที่แท้จริงเพียงใด สิ่งนี้ซับซ้อนกว่าข้อผิดพลาดทั่วไป เนื่องจากเรากำลังจัดการกับความน่าจะเป็น ไม่ใช่ค่าที่แน่นอน
องค์ประกอบบันทึก-ความน่าจะเป็น:
=IF(B2=1,LN(MAX(G2,0.0001)),LN(MAX(1-G2,0.0001)))

- สำหรับผลลัพธ์ไบนารี่ เราไม่สามารถใช้การลบแบบง่าย (ตามจริง – คาดการณ์) ได้
- แต่เราวัดว่าเรา "ประหลาดใจ" แค่ไหนจากผลลัพธ์จริงตามการคาดการณ์ของเรา
- หากเราคาดการณ์โอกาส 90% ที่จะซื้อและลูกค้าซื้อ เราก็ไม่แปลกใจเลย (รูปแบบที่ดี)
- หากเราคาดการณ์โอกาส 10% ที่จะซื้อและลูกค้าซื้อ เราก็จะประหลาดใจมาก (รูปแบบที่ไม่ดี)
ขั้นตอนที่ 5:ตั้งค่าเมตริกโมเดลลอจิสติก
สร้างการวัดประสิทธิภาพการจำแนกประเภทที่เกี่ยวข้องกับธุรกิจ ตัวชี้วัดเหล่านี้ช่วยในการตัดสินใจว่าโมเดลนี้ดีเพียงพอสำหรับการตัดสินใจทางธุรกิจจริงหรือไม่
ความแม่นยำสูงหมายถึงการสิ้นเปลืองเงินทางการตลาดน้อยลง (ผลบวกลวงต่ำ) การเรียกคืนที่สูงหมายความว่าเราไม่พลาดผู้มีโอกาสเป็นลูกค้า (ผลลบลวงต่ำ)
ตัวชี้วัดลอจิสติก:
- โมเดลความพอดี/บันทึกเชิงลบ-ความน่าจะเป็น: ค่าที่ต่ำกว่าหมายถึงการคาดการณ์ความน่าจะเป็นที่ดีขึ้น
- ความแม่นยำ: เปอร์เซ็นต์ของลูกค้าจัดประเภทอย่างถูกต้อง (หากเราใช้ 50% เป็นจุดตัด)
=SUMPRODUCT((G2:G11>0.5)*(B2:B11=1)+(G2:G11<=0.5)*(B2:B11=0))/10
- ความแม่นยำ: ลูกค้าที่เราคาดการณ์ไว้จะซื้อกี่เปอร์เซ็นต์ และซื้อกี่เปอร์เซ็นต์
=IF(SUMPRODUCT((G2:G11>0.5))=0,"No Predictions",SUMPRODUCT((G2:G11>0.5)*(B2:B11=1))/SUMPRODUCT((G2:G11>0.5)))
- เรียกคืน: ลูกค้าที่ซื้อกี่เปอร์เซ็นต์ เราระบุได้กี่เปอร์เซ็นต์
=SUMPRODUCT((G2:G11>0.5)*(B2:B11=1))/SUMPRODUCT(B2:B11)
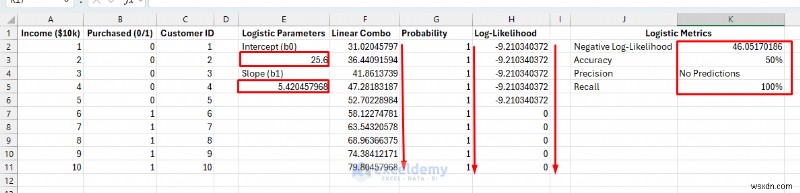
ขั้นตอนที่ 6:ปรับโมเดลโลจิสติกส์ให้เหมาะสมด้วย Solver
ค้นหาค่าพารามิเตอร์ที่เหมาะสมกับรูปแบบความน่าจะเป็นในข้อมูลมากที่สุด Solver จะลดโอกาสการบันทึกเชิงลบให้เหลือน้อยที่สุด ซึ่งจะเพิ่มความน่าจะเป็นสูงสุดในการสังเกตข้อมูลจริง
- ไปที่ ข้อมูล แท็บ>> เลือก ตัวแก้ปัญหา .
- กำหนดวัตถุประสงค์:K2 (บันทึกเชิงลบ-ความน่าจะเป็น)
- ถึง:ขั้นต่ำ .
- โดยการเปลี่ยนเซลล์ตัวแปร:E3,E5 .
- คลิก แก้ปัญหา .
แก้ไขปัญหาทั่วไป
- ตัวแก้ปัญหาไม่มาบรรจบกัน :ลองใช้ค่าเริ่มต้นอื่นหรือเพิ่มการวนซ้ำ
- ค่า R เชิงลบ :ตรวจสอบข้อผิดพลาดในการป้อนข้อมูลหรือข้อมูลจำเพาะของรุ่น
- การแยกส่วนที่สมบูรณ์แบบในด้านลอจิสติกส์ :ลดค่าคุณลักษณะหรือเพิ่มการทำให้เป็นมาตรฐาน
บทสรุป
บทช่วยสอนนี้แสดงขั้นตอนทีละขั้นตอนเพื่อสร้างโมเดลการเรียนรู้ของเครื่องโดยตรงใน Excel แม้ว่า Excel จะมีข้อจำกัดเมื่อเทียบกับเครื่องมือ ML เฉพาะทาง แต่ก็ให้ความโปร่งใสและการเข้าถึงเพื่อทำความเข้าใจกลไกของแบบจำลอง ด้วยการใช้ Solver ของ Excel และสูตรพื้นฐาน คุณจะสามารถนำโมเดล Machine Learning แบบน้ำหนักเบาเหล่านี้ไปใช้ได้อย่างรวดเร็ว แสดงภาพการคาดการณ์ และทำความเข้าใจความแม่นยำของโมเดลด้วยวิธีที่เรียบง่ายแต่ให้ข้อมูลเชิงลึก เทคนิคที่แสดงที่นี่สามารถขยายไปยังสถานการณ์ที่ซับซ้อนมากขึ้นและใช้เป็นเครื่องมือทางการศึกษาสำหรับการเรียนรู้แนวคิดการถดถอย
รับแบบฝึกหัด Excel ขั้นสูงพร้อมโซลูชันฟรี!