
งานเบื้องหลังถือเป็นเสาหลักประการหนึ่งเมื่อพิจารณาถึงขนาดแอปพลิเคชันบนเว็บ แนวคิดพื้นฐานนั้นเรียบง่าย:ลูกค้าส่งคำขอไปยังเว็บแอปพลิเคชันของคุณ และในการจัดการคำขอนั้น แอปของคุณจะทำงานที่ใช้เวลานานหลายอย่าง เพื่อให้สามารถตอบสนองลูกค้าได้เร็วขึ้น แอปจะจัดคิวงานเบื้องหลังให้กับระบบประมวลผลเบื้องหลัง จากนั้น การประมวลผลเบื้องหลังจะถูกมอบหมายให้ทำหน้าที่ยกของหนักทั้งหมด เช่น การคำนวณหรือการดำเนินการ I/O การพึ่งพางานเบื้องหลังอย่างมีประสิทธิภาพถือเป็นองค์ประกอบสำคัญประการหนึ่งเมื่อปรับขนาดแอปพลิเคชันเว็บของคุณ
ในฐานะนักพัฒนา Rails เรามีไลบรารีที่ยอดเยี่ยมมากมายให้เลือก ทั้งหมดนี้มีข้อดี ข้อเสีย และแม้แต่ฐานข้อมูลแบ็กเอนด์ที่แตกต่างกัน ไลบรารีเหล่านี้ทำให้ง่ายต่อการขนถ่ายงานหนัก ช่วยให้แอปพลิเคชันของเราตอบสนองได้รวดเร็วยิ่งขึ้น และให้บริการผู้ใช้ได้มากขึ้นโดยใช้ทรัพยากรน้อยลง
จนกระทั่งเมื่อไม่นานมานี้ เราใช้ Sidekiq เพื่อดำเนินงานการประมวลผลเบื้องหลังส่วนใหญ่ของ Honeybadger ข้อมูลนี้มีประโยชน์ในการช่วยให้เรารักษาประสบการณ์ผู้ใช้ที่รวดเร็วเป็นพิเศษและเป็นไปป์ไลน์ที่มีประสิทธิภาพสำหรับการประมวลผลข้อมูลจำนวนมหาศาลที่เรานำเข้า
Sidekiq ขาดเราตรงไหน
แม้จะมีความน่าเชื่อถือ Redis ก็มีข้อจำกัดบางประการ จนกระทั่งเมื่อไม่นานมานี้ เราใช้ Sidekiq สำหรับการประมวลผลงานทั้งหมดของเรา รวมถึงการจัดการการนำเข้าสำหรับจุดสิ้นสุดการติดตามข้อผิดพลาดของเรา การรับส่งข้อมูลที่มีข้อผิดพลาดมีความผันแปรสูง เรามักจะเพิ่มจำนวนงานในคิวของเราเป็น 10 เท่าหรือ 20 เท่า ซึ่งส่งผลให้มีงานค้างจำนวนมากจนกว่าการปรับขนาดอัตโนมัติของเราจะดึงคนทำงานมากพอที่จะตามให้ทัน แต่ปัญหาที่ใหญ่กว่าคือหน่วยความจำหมดในคลัสเตอร์ ElastiCache ของเรา
เรามีปริมาณงานเพียงพอที่ส่งผ่านคลัสเตอร์ ElastiCache ของเรา ซึ่งความล่าช้าที่สำคัญในการประมวลผลดาวน์สตรีมอาจเสี่ยงที่คลัสเตอร์จะหน่วยความจำไม่เพียงพอ แม้ว่าเราจะใช้คลัสเตอร์แยกต่างหากสำหรับการจัดเก็บข้อมูลที่ไม่ใช่คิว เมื่อเวลาผ่านไป เราก็มีข้อมูลที่ไม่ใช่คิวแสดงอยู่ในคลัสเตอร์หลักเช่นกัน ซึ่งอาจถูกไล่ออกในกรณีข้อผิดพลาดหน่วยความจำไม่เพียงพอ อย่างไรก็ตาม ปัญหาที่สำคัญกว่านั้นคือไม่สามารถรับงานใหม่ได้เมื่อคลัสเตอร์มีหน่วยความจำไม่เพียงพอ
ปัญหารองคือ Redis/ElastiCache ใช้ 01 นโยบายการขับไล่โดยค่าเริ่มต้น ผลที่ตามมาคือในช่วงเวลาที่มีการใช้งานหน่วยความจำสูง Redis จะลบข้อมูลที่ใช้น้อยที่สุดล่าสุดด้วยชุด TTL จนถึงจุดหนึ่ง Honeybadger มีเหตุการณ์ที่การใช้หน่วยความจำของเราสูงพอที่จะทำให้ Redis เริ่มล้างแคชโดยที่เราไม่ได้ตั้งใจ โชคดีที่ข้อมูลที่ขับไล่ออกไปนั้นสามารถทำซ้ำได้ (ซึ่งก็คือ TTL) ดังนั้นเราจึงไม่สูญเสียข้อมูลถาวรใดๆ
ถึงกระนั้น สิ่งนี้ทำให้เรามีคำถามหนึ่งที่ต้องแก้ไข - จะเกิดอะไรขึ้นหากมีเหตุการณ์ที่คล้ายกันเกิดขึ้นและเราเริ่มสูญเสียข้อมูลที่เราไม่สามารถสร้างใหม่ได้ เราจะมั่นใจได้อย่างไรว่าเราจะไม่สูญเสียข้อมูลลูกค้า? การจัดการข้อมูลข้อผิดพลาดของลูกค้าถือเป็นหัวใจสำคัญของธุรกิจของเรา ดังนั้น เราจำเป็นต้องมีระบบที่ทนทานต่อการสูญเสียข้อมูล
การใช้ Kafka เพื่อนำเข้าข้อมูล
Kafka เป็นไปป์ไลน์เหตุการณ์แบบกระจายที่ให้ทั้งความสามารถในการปรับขนาดและความยืดหยุ่น ด้วยการเปิดตัว Insights เมื่อเร็วๆ นี้ เราได้รับประสบการณ์มากมายในการทำให้ Kafka เป็นโครงสร้างพื้นฐานในการประมวลผลข้อมูลกิจกรรมของเรา หลังจากนั้น เราต้องการใช้กลุ่มเทคโนโลยีเดียวกันเพื่อประมวลผลข้อมูลการนำเข้าข้อผิดพลาดของเรา เรามุ่งหวังที่จะบรรลุพื้นที่จัดเก็บข้อมูลสำรองพร้อมความสามารถในการขยายที่ดีขึ้นและต้นทุนที่เอื้อมถึงมากขึ้นโดยใช้ Kafka
เนื่องจากเราใช้งานคลัสเตอร์ AWS MSK สำหรับ Insights ของเราเอง เราจึงมีโครงสร้างพื้นฐานและการตั้งค่าการปรับขนาดอัตโนมัติอยู่แล้ว ซึ่งหมายความว่าเรา "เพียงแค่" ต้องตั้งหัวข้อสองสามหัวข้อและสร้างผู้บริโภคเพียงไม่กี่รายที่ใช้โค้ดเดียวกันกับที่พนักงาน Sidekiq ของเราทำ แนวคิดนี้ค่อนข้างเรียบง่ายซึ่งช่วยให้เรามุ่งเน้นไปที่การปรับแต่งผู้บริโภค Kafka ของเราได้มากขึ้น
การย้ายจาก Sidekiq ไปยัง Karafka
Honeybadger ได้รับการออกแบบทางสถาปัตยกรรมให้เป็นหินใหญ่ก้อนเดียว และ Karafka ก็ช่วยให้เรารักษาสถาปัตยกรรมแบบเดียวกันนั้นไว้ได้ เราใช้ Karafka เพื่อประมวลผลข้อมูลเชิงลึกบางส่วนของเราแล้ว ดังนั้นการเพิ่มผู้บริโภครายใหม่เพียงไม่กี่รายจึงเป็นเรื่องง่าย
ความแตกต่างหลักประการหนึ่งระหว่าง Karafka และ Sidekiq คือวิธีการดึงงานกลับมา ด้วย Karafka งานต่างๆ จะถูกจัดเป็นชุดและประมวลผลร่วมกันในการดำเนินการโดยผู้บริโภครายเดียว สำหรับผู้ใช้ทั่วไป เราสามารถวนซ้ำอาร์เรย์ของข้อความและเรียกใช้ผู้ปฏิบัติงาน Sidekiq แบบอินไลน์:
class NoticeConsumer < ApplicationConsumer
def consume
messages.each do |message|
NoticeWorker.new.perform(message.payload)
end
end
end
ข้อแตกต่างอีกประการหนึ่งที่เราต้องพิจารณาคือวิธีการจัดการข้อผิดพลาดทำงานอย่างไร ด้วย Sidekiq เนื่องจากแต่ละงานเป็นแบบอะตอมมิก ผู้ปฏิบัติงานจึงจัดการกับข้อผิดพลาดของตัวเองผ่านการลองใหม่และการเรียกกลับเมื่อล้มเหลว ด้วยพฤติกรรมการแบทช์ของ Kafka มีตัวเลือกเพิ่มเติมในการจัดการข้อผิดพลาด สิ่งที่โดดเด่นที่สุดคือ Karafka มีกลไกที่เรียกว่า Dead Letter Queue ซึ่งช่วยให้คุณสามารถระบุการจัดการข้อผิดพลาดเป็นชุดหรือเป็นรายบุคคลได้
dead_letter_queue(
topic: "ingestion.errors.dead",
max_retries: 5,
independent: true
)
เมื่อใดก็ตามที่ผู้บริโภค Karafka ประสบความล้มเหลวในการประมวลผลข้อความแต่ละรายการ ผู้ใช้จะพยายามประมวลผลซ้ำ 5 ครั้ง หากไม่สำเร็จในครั้งที่ 5 ข้อความจะถูกส่งไปยังหัวข้อที่ระบุ 19 ตัวเลือกบอกผู้บริโภคว่าต้องส่งเฉพาะข้อความที่ล้มเหลวไปยัง DLQ แทนที่จะส่งทั้งชุด
การตรวจสอบและปรับขนาด Karafka
ปรากฎว่าการติดตามและปรับขนาดผู้บริโภค Karafka ค่อนข้างซับซ้อน มีหลายสิ่งที่คุณสามารถติดตามได้จากทั้ง AWS/MSK และ Karafka และปุ่มต่างๆ มากมายที่คุณสามารถหมุนเพื่อปรับแต่งระบบของคุณได้ ต้องให้ความสนใจอย่างระมัดระวังต่อสิ่งที่โค้ดของคุณกำลังทำ รวมถึงพฤติกรรมของกระแสข้อมูล
ด้วย AWS CloudWatch เราตรวจสอบสิ่งต่างๆ มากมาย แต่นี่คือตัววัดเฉพาะของ Kafka บางส่วนที่เราพิจารณา:
- SumOffsetLag — สำหรับหัวข้อและกลุ่มผู้บริโภคที่ระบุ นี่คือผลรวมของความล่าช้าออฟเซ็ตทั้งหมดในทุกพาร์ติชัน
- MaxTimeLag โดยประมาณ — สำหรับหัวข้อและกลุ่มผู้บริโภคที่ระบุ นี่คือ โดยประมาณ ระยะเวลาที่ใช้ในการไล่ตามพาร์ติชันทั้งหมดให้ถึงออฟเซ็ตปัจจุบัน
Karafka ยังมีเครื่องมือที่ยอดเยี่ยม แต่คุณจะต้องเผยแพร่ข้อมูลนี้และเก็บไว้ด้วยตัวเอง:
- processing_lag * — ค่านี้ใช้ได้กับข้อความทุกชุดที่ใช้ไป โดยจะแจ้งให้คุณทราบถึงเวลาที่ Karafka ใช้ในการรับข้อความจาก Kafka และเริ่มประมวลผล
- การบริโภค_lag * — ค่านี้คล้ายกับ processing_lag ยกเว้นเวลาที่ข้อความสุดท้ายของชุดเข้าสู่ระบบ Kafka จนกระทั่งผู้บริโภคของคุณเริ่มประมวลผล
- ระยะเวลา * — นี่คือเวลาที่ผู้บริโภคใช้ในการประมวลผลข้อความทั้งชุด
ปรากฎว่าการปรับขนาดกระบวนการ Sidekiq นั้นแตกต่างจากการปรับขนาดกระบวนการผู้บริโภคของ Karafka อย่างมาก เมื่อเพิ่มความขนานของ Sidekiq คุณสามารถเพิ่มกระบวนการต่างๆ ให้กับอินสแตนซ์ Redis ของคุณสามารถจัดการได้ ด้วย Kafka คุณจะต้องมีกระบวนการสูงสุด 1 กระบวนการต่อพาร์ติชันในหัวข้อของคุณ ตามกฎทั่วไป คุณจะต้องมีพาร์ติชั่นมากกว่าที่คุณวางแผนไว้ เนื่องจาก Kafka Consumer สามารถกำหนดพาร์ติชั่นได้มากกว่า 1 พาร์ติชั่น
อีกสิ่งหนึ่งที่ควรจำก็คือการขยายขนาดและลดขนาดผู้บริโภค Kafka อาจเป็นการดำเนินการที่ใช้เวลานานมาก การเพิ่มและลบผู้บริโภคออกจากกลุ่มผู้บริโภคทำให้กลุ่มต้องปรับสมดุลตัวเอง นี่หมายถึงการกำหนดพาร์ติชันใหม่ตามความจำเป็น ในระหว่างการมอบหมายใหม่ ผู้บริโภคจะหยุดประมวลผลข้อความ แม้ว่าคุณจะสามารถบรรเทาปัญหานี้ได้บ้างด้วย 21 โดยทั่วไปคุณต้องการหลีกเลี่ยงการปรับสมดุลหากทำได้โดยการจัดสรรทรัพยากรมากเกินไป
ขณะนี้เรากำลังตรวจสอบ 33 เป็นหนึ่งในตัวชี้วัดการปรับขนาดของเรา สิ่งสำคัญที่ควรทราบคือในระหว่างการปรับสมดุล ตัววัดนี้จะไม่ได้รับการรายงาน ตามที่คุณสามารถจินตนาการได้ ในระหว่างช่วงการปรับสมดุล ตัวชี้วัดนี้จะเพิ่มขึ้นอย่างมากจนกว่าการปรับสมดุลจะเสร็จสิ้น นี่เป็นอีกเหตุผลหนึ่งที่จำเป็นต้องปรับขนาดให้น้อยที่สุด
อะไรต่อไปสำหรับ Karafka ที่ Honeybadger
เรากำลังดำเนินการใช้งาน Kafka/Karafka 100% มานานกว่าหนึ่งเดือนแล้ว และปลอดภัยที่จะบอกว่าเราค่อนข้างพอใจ อย่างไรก็ตาม เป็นเรื่องดีที่รู้ว่าเราสามารถกลับไปหา Sidekiq ได้ตลอดเวลาด้วยการกดปุ่มเพียงปุ่มเดียวหากจำเป็น สิ่งนี้ทำให้เรามีความยืดหยุ่นมากยิ่งขึ้นเมื่อจำเป็นต้องบำรุงรักษาระบบใดๆ เหล่านี้
ในกระบวนการย้ายจาก Sidekiq ไปยัง Karafka เรายังได้เรียนรู้อีกมากมายเกี่ยวกับการทำงานร่วมกับ Kafka และ Karafka หากคุณยังไม่ได้อัปเดต Honeybadger gem เวอร์ชันล่าสุด คุณควรลองดู! ฉันเพิ่มคุณสมบัติใหม่ให้กับปลั๊กอิน karafka เมื่อคุณเปิดใช้งานข้อมูลเชิงลึก Gem ของเราจะเริ่มติดตามสถิติที่สำคัญเพื่อให้คุณเห็นภาพรวมของระบบ Kafka ของคุณได้ดีขึ้น
นอกจากนี้ ขณะนี้เรามีแดชบอร์ดข้อมูลเชิงลึก Karakfa เพื่อช่วยให้คุณเห็นภาพข้อมูลนี้ และช่วยให้คุณเข้าใจพฤติกรรมผู้บริโภค Kafka ของคุณได้ดียิ่งขึ้น Karafka Dashboard กำหนดให้ต้องเปิดใช้งานเมตริกสำหรับปลั๊กอิน หากต้องการทำเช่นนั้นให้เพิ่มการกำหนดค่าต่อไปนี้ใน 40 ของคุณ :
karafka:
insights:
metrics: true
ต่อไปนี้คือตัวอย่างลักษณะแดชบอร์ด:
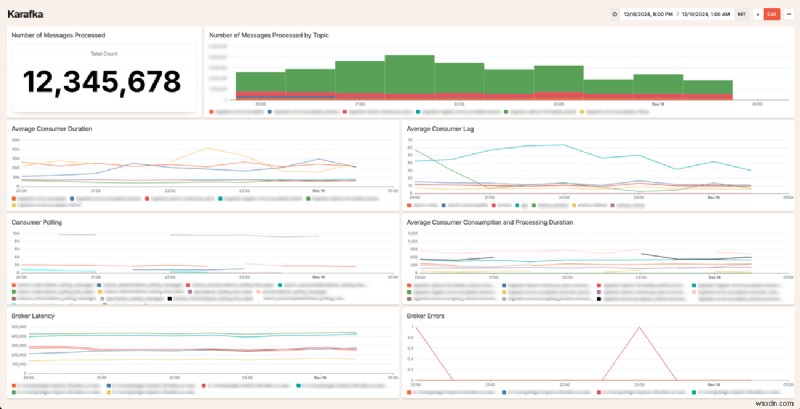
เรารู้สึกตื่นเต้นที่ได้เห็นว่าลูกค้าของเราใช้ข้อมูลนี้เพื่อปรับปรุงระบบ Kafka ของตนเองอย่างไร หากคุณมีคำถามใดๆ เกี่ยวกับวิธีที่เราย้ายจาก Sidekiq ไปยัง Karafka หรือวิธีที่เราใช้ Kafka โดยทั่วไป โปรดติดต่อเรา!
